
Com o avanço tecnológico, assuntos comoa inteligência artificial e machine learning estão ganhando espaço na vida das pessoas, já que elas podem auxiliar na proteção contra ataques cibernéticos e vulnerabilidades em geral. Dentre os conceitos existentes na área do aprendizado de máquina, encontra-se o aprendizado não supervisionado.
Sabendo como é feito um aprendizado não supervisionado, você pode ter uma economia de tempo significativa e um ganho alto de produtividade em sua empresa. Então, vamos conhecer mais a fundo como funciona esse tipo de aprendizado e seus principais conceitos?
- O que é o aprendizado não supervisionado e como funciona?
- Quais os benefícios de usar o aprendizado não supervisionado?
- Quais as desvantagens do aprendizado não supervisionado?
- Quais os tipos de aprendizado não supervisionado?
- Entenda a clusterização no aprendizado não supervisionado!
- Como funciona a associação de dados no aprendizado não supervisionado?
- Como funciona a detecção de anomalias no aprendizado não supervisionado?
- Como funcionam os modelos de variáveis latentes no aprendizado não supervisionado?
- Aprendizado supervisionado, não supervisionado, semi supervisionado e por reforço: qual é o melhor?
- Quais as aplicações práticas do aprendizado não supervisionado?
O que é o aprendizado não supervisionado e como funciona?
O aprendizado não supervisionado é uma forma em que o aprendizado de máquina ocorre de forma independente. Nesse caso, o algoritmo deve tentar entender a rotina por conta própria devido à ausência da rotulação de dados, ou seja, não sabemos quais as saídas que o algoritmo terá.
Assim, o algoritmo em questão não passará por nenhum tipo de tratamento dos dados e deverá descobrir por si mesmo as relações entre os dados. Depois disso, ele verifica se há alguma equivalência com os dados para que eles sejam agrupados. Como não temos os dados rotulados, não precisará ser feito nenhum tipo de teste.
Vejamos a seguir um diagrama que representa o fluxo do aprendizado não supervisionado:
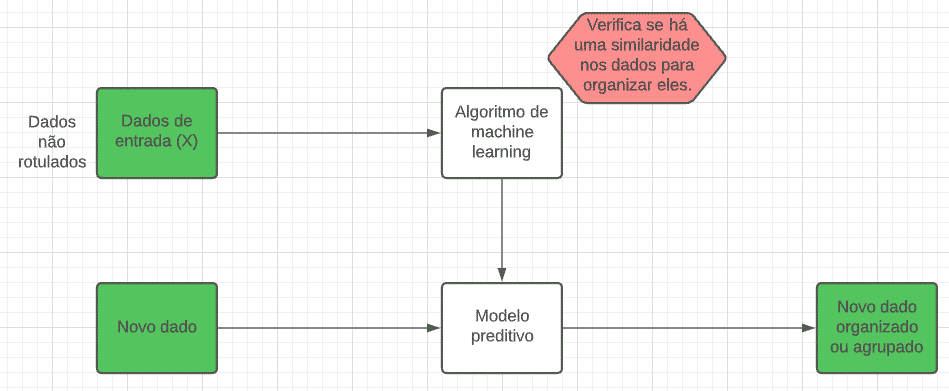
Um exemplo disso em nosso cotidiano seria dirigir um carro pela primeira vez. Sem a supervisão de ninguém, você certamente terá dificuldades para pilotar um automóvel, sobre o que cada parte do carro faz, como ativar o pára-brisa, como funciona a embreagem, etc. Ou seja, isso caracteriza um aprendizado não supervisionado.
Já com a supervisão de uma pessoa instrutora ou familiar — que seria o aprendizado supervisionado (conceito que será explicado mais a fundo nas seções seguintes) — você saberá qual exatamente a função do freio, da embreagem, do volante, do câmbio de marchas, etc.
Entendi! Então, quer dizer que a aprendizagem não supervisionada é o processo de um algoritmo entender por conta própria o que é feito no código, sem a ajuda de cientistas de dados? Isso mesmo!
Vejamos a seguir um pouco sobre o que quer dizer o conceito de machine learning, um complemento ao assunto do aprendizado de máquina.
O que é o machine learning?
Machine learning é um algoritmo que não necessita a utilização de instruções para ser executado. Ou seja, com base em dados, o próprio algoritmo se encarregará de resolver o problema sozinho.
No aprendizado de máquina (machine learning), ao invés de serem feitas programações para resolver situações específicas, os equipamentos utilizam algoritmos de alta complexidade para a tomada de decisões e realizar tarefas de forma automática. Nesse caso, os programas aprendem sem qualquer ação humana, apenas com a interpretação do processamento de dados.
Existem alguns pilares a serem seguidos em qualquer projeto de machine learning. São eles:
- Entendimento do problema e definição de objetivos — Que problema estou resolvendo?
- Coleta e análise de dados — De quais informações eu preciso?
- Preparação dos dados — Como os dados serão tratados e de que forma?
- Construção do modelo — Quais são os padrões nos dados que levam a soluções?
- Avaliar e verificar o modelo — O modelo resolve meu problema?
- Exibição de resultados — Como posso resolver o problema?
- Distribuição do modelo — Como resolver o problema no mundo real?
Quais os benefícios de usar o aprendizado não supervisionado?
As vantagens de se utilizar o aprendizado não supervisionado são as seguintes:
- Possibilidade de trabalhar com dados desconhecidos;
- Não necessita conhecer todos os itens do conjunto;
- Possibilidade de reconhecer fraudes;
- Identificação de oportunidades de marketing com base em lojas virtuais e em desejos da pessoa usuária.
Quais as desvantagens do aprendizado não supervisionado?
Para trabalhar com o aprendizado não supervisionado é necessário ter um nível de conhecimento alto em manipulação de dados, pois, como não haverá interação humana nesse tipo de aprendizado, a manipulação de dados deve ser feita de forma correta.
Caso contrário, a desvantagem será que os resultados podem não ser os esperados após a execução do algoritmo. Existem dois tipos de aprendizado não supervisionado, que serão exibidos no tópico seguinte.
Quais os tipos de aprendizado não supervisionado?
Modelos Generativos
Modelos generativos funcionam a partir de predições: se você disser que a entrada será um valor X e a consequência for um valor Y, ele dirá a probabilidade de X e Y serem vistos ao mesmo tempo. No modelo generativo podemos fornecer qualquer entrada (conhecida ou não) e solicitar uma resposta.
Modelos Discriminativos
Modelos discriminativos não possuem capacidade preditiva e funcionam a partir da atribuição de rótulos nas entradas fornecidas: se você disser que a entrada será um valor X, a consequência será um valor Y. Ou seja, se for fornecido um valor X desconhecido, não poderá dizer qual será o valor Y, pois você desconhece o valor do X.
Unindo os dois modelos acima em um exemplo: a professora de uma sala analisa quais estudantes terminaram a sua prova ao meio-dia e qual a probabilidade disso ocorrer de novo. Em um modelo discriminativo, ela analisaria somente o horário do meio-dia. Já em um modelo generativo, ela analisa o contexto entre os horários das 11:59 da manhã e 12:30 da tarde, para dar uma resposta mais precisa.
Entenda a clusterização no aprendizado não supervisionado!
A clusterização significa o agrupamento dos objetos em subconjuntos chamados clusters. Com eles, você consegue ter um bom dimensionamento de como está a estrutura de seus dados. A seguir, veremos algumas técnicas de realizar esse agrupamento:
Agrupamentos difusos
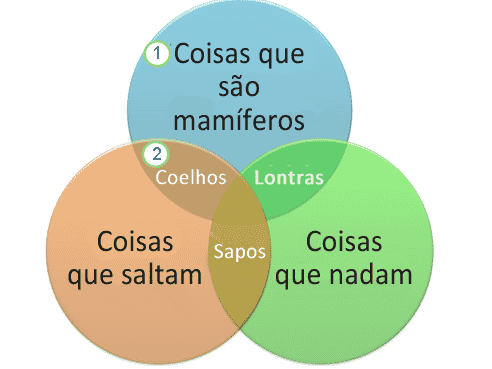
Você, caso já tenha visto um pouco sobre conjuntos na Matemática, deve se lembrar do diagrama de Venn, conforme foto acima. O agrupamento difuso é similar ao diagrama de Venn, sendo que, cada ponto de dados pode ter vários clusters.
Contudo, como existem relacionamentos entre grupos, nem sempre é o caso mais recomendado para segmentar os dados, pois o agrupamento difuso não trata os pontos de dados como pessoas.
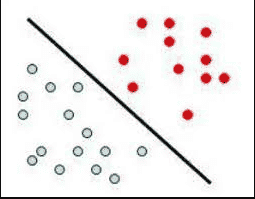
Vejamos, a seguir, um exemplo de agrupamento difuso:
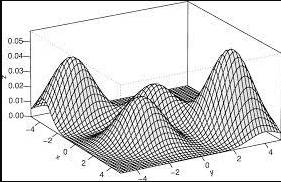
Modelos de mistura gaussiana
Baseado em uma distribuição normal, os agrupamentos são feitos de acordo com as densidades esperadas, exibindo subpopulações nas colunas.
Vejamos a seguir, um exemplo de agrupamento utilizando o modelo de mistura gaussiana:
Agrupamento hierárquico
É o agrupamento que ocorre como se fosse uma árvore de clusters. Todos os dados recebidos são um cluster e é feita a divisão destes em partes menores, formando uma cascata, desde os mais simples até os mais complexos. Vejamos na imagem a seguir um exemplo de agrupamento hierárquico:
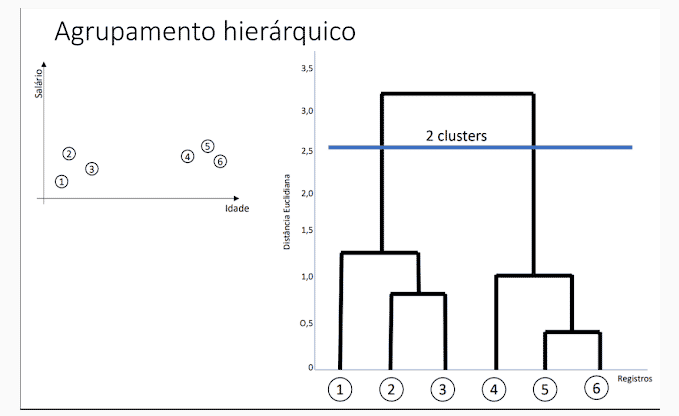
Agrupamento de k-médias
Os clusters não rotulados nos dados são separados do algoritmo. Um cluster pode pertencer a somente um ponto de dados. Se o k for um resultado maior, quer dizer que existe um grupo menor com mais granularidade da mesma maneira. Dessa forma, para cada cluster, é feita a atribuição de um rótulo de ponto de dados.
Vejamos a seguir, um exemplo de agrupamento utilizando o k-médias:
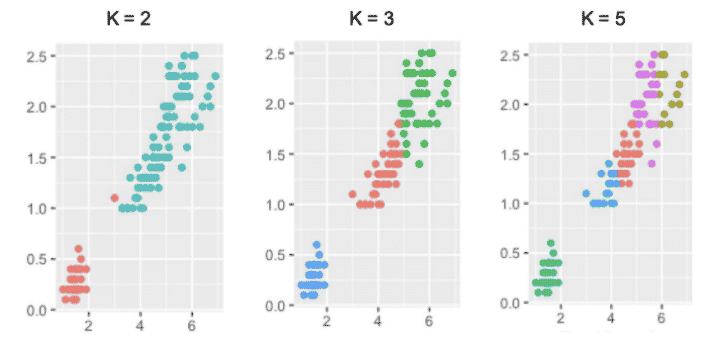
Como funciona a associação de dados no aprendizado não supervisionado?
Na associação de dados presente no aprendizado não supervisionado, o algoritmo estabelece alguns critérios que localizam similaridades entre os pontos de dados. Ele localiza equivalência entre as variáveis, indicando itens ou ações que possam ocorrer juntos.
Um exemplo disso seria analisar quais itens as pessoas compram simultaneamente em uma padaria ou supermercado, como pão e molho de tomate. Além disso, essa técnica pode ser vista em apresentar novos serviços e produtos aos clientes, como o interesse que uma pessoa tem ao ver um produto, se ela costuma comprar algum outro, etc.
O algoritmo de associação é altamente recomendado para a identificação de oportunidades de marketing.
Como funciona a detecção de anomalias no aprendizado não supervisionado?
A detecção de anomalias verifica dados incomuns, que estejam fora da curva em um conjunto de dados. Por exemplo, compras acima do permitido em um cartão de crédito, descobrimento de doenças, dados discrepantes com base em informações erradas fornecidas por humanos, dentre outros.
Como funcionam os modelos de variáveis latentes no aprendizado não supervisionado?
Os modelos de variáveis latentes são utilizados, na maior parte das vezes, na limpeza dos dados e no pré-processamento deles. Com isso, há a redução dos recursos em um único conjunto de dados ou pode ser realizada a divisão do conjunto de dados em vários outros componentes menores.
Aprendizado supervisionado, não supervisionado, semi supervisionado e por reforço: qual é o melhor?
Vejamos a tabela a seguir, com uma pequena definição do que cada aprendizado significa:
| Aprendizado supervisionado | O algoritmo entende o que está sendo realizado com o auxílio da intervenção humana. |
| Aprendizado não supervisionado | O algoritmo entende o que está sendo realizado sozinho, sem a intervenção humana. |
| Aprendizado semi supervisionado | Somente alguns dados de uma grande quantidade é supervisionado. |
| Aprendizado por reforço | A máquina verifica qual a melhor ação a ser tomada, baseada nas circunstâncias que estão ocorrendo no momento. |
Para escolher qual é o melhor, dependerá de qual a análise você está fazendo, pois, cada problema pode ter muitas maneiras de ser resolvido e cada um possui as suas particularidades. Se você testar a solução A em uma situação, ela pode ter um resultado bom, mas em outra situação, o resultado pode não ser o esperado.
Nesse caso, não existe certo ou errado na tecnologia com escolhas de aprendizado, por exemplo. O contexto do problema deverá ser analisado e, a partir disso, a solução que melhor se encaixa deverá ser utilizada.
Quais as aplicações práticas do aprendizado não supervisionado?
Na Amazon, existe a técnica de clusterização para fazer recomendações de vendas de forma customizada para cada cliente. Técnica utilizada também por empresas como o Youtube, Netflix, para a recomendação de produtos, baseado na navegação realizada pela pessoa usuária.
Além disso, existe uma técnica utilizada no aprendizado não supervisionado para detecção de anomalias, ou seja, de atos que saíam do padrão do aceitável, como, por exemplo, fraudes em cartões de crédito, defeitos em equipamentos diversos, dentre outros.
Conclusão
O aprendizado não supervisionado é um aprendizado que não necessita da intervenção humana para o funcionamento, ou seja, o algoritmo precisa entender o que está sendo feito. Existem modelos para o aprendizado não supervisionado, o generativo (reconhece variáveis desconhecidas → predição) e o discriminativo (não reconhece variáveis desconhecidas).
Além disso, há modelos que podem detectar anomalias em um conjunto de dados e eventos que fazem associações entre eventos que possam ocorrer de forma simultânea. Da mesma forma, para haver uma redução dos recursos e uma possível divisão de um conjunto de dados em parte menores, são utilizadas as variáveis latentes.
Para aprofundar os seus conhecimentos em aprendizado de máquina, confira esse artigo de como funcionam as redes neurais artificiais.


