
Do inglês, clusterizar significa agrupar, colocar no mesmo grupo ou reunir. No mundo do big data e do machine learning, por exemplo, a clusterização é uma ferramenta fundamental na separação de dados.
Afinal, a melhor maneira de analisar um grande volume de informações é clusterizando as informações.
Nesse artigo, entre outros temas, vamos também entender a relação com machine learning e falar sobre as principais aplicações da clusterização.
Fique com a gente!
- O que é a clusterização?
- Quais os benefícios da clusterização?
- Quais as desvantagens da clusterização?
- Qual a relação entre a clusterização e o aprendizado não supervisionado?
- Quais são os tipos de clusterização?
- Quais os 4 tipos de algoritmos de clusterização?
- Quais os 5 principais algoritmos de clusterização?
- Quais as diferenças entre classificação e clusterização?
- Quais as principais aplicações da clusterização?
O que é a clusterização?
Clusterizar significa agrupar, categorizar e até mesmo organizar qualquer tipo de dados de acordo com suas características que são incomuns, sejam elas: cor, tamanho, tipo ou peso.
Ou seja, separar os grupos com características semelhantes e atribuí-los em potes, ou, neste caso, em clusters.
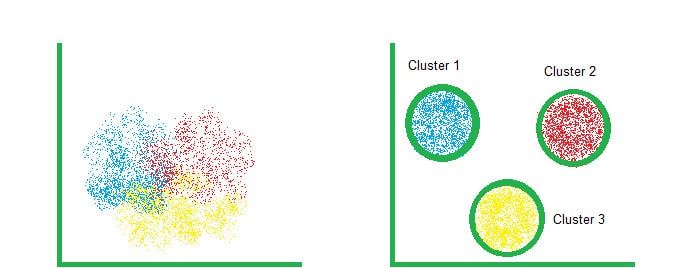
Qual a relação do machine learning com a clusterização?
Digamos que esteja querendo aprender sobre música. Uma abordagem a ser usada pode ser procurar bandas ou coletâneas que marcaram época. Você pode organizar a música por gênero, por década, por idioma e por aí vai.
A forma como você escolhe clusterizar os itens ajuda a entender mais sobre eles como peças musicais individuais. Você pode descobrir, por exemplo, que tem uma afinidade profunda com o punk rock da década de 1980 e encontrar uma banda que não estaria no seu radar sem esse recorte.
Ainda é possível dividir as músicas que foram trilhas sonoras em filmes antigos e descobrir uma canção linda, por exemplo, dos anos 1950.
Trazendo a conversa para a tecnologia…
… no aprendizado de máquina não é diferente. Geralmente agrupamos dados como um primeiro passo para entender um assunto, no caso, um conjunto de dados, como é chamado na área de machine learning.
Ou seja, a clusterização, muitas vezes, serve como uma primeira camada de análise para se trabalhar um volume de dados que precisa ser analisado. Não resolve o problema e nem é suficiente para fazer uma análise, mas ajuda a começar a resolver ou entender.
Quais os benefícios da clusterização?
Em uma simples análise, podemos observar que clusterizar uma quantidade de informações dentro do universo da TI pode trazer grandes benefícios, ainda mais quando se trata de dados. Algumas vantagens de utilizar a clusterização são:
- Melhorar a organização de dados;
- Otimizar processos;
- Fácil manutenção caso seja necessário realizar uma busca em um banco de dados com milhares de informações;
- Facilidade em adicionar mais dados;
- Outras pessoas podem ter acesso a esses dados de maneira organizada.
Quais as desvantagens da clusterização?
Infelizmente, ainda existe uma boa quantidade de pessoas que não utilizam o processo de clusterização e isso acaba se tornando uma grande desvantagem para as empresas.
Além disso, outras desvantagens da clusterização são:
- A dificuldade em recuperar um banco de dados que foi corrompido;
- Seus algoritmos são de grande complexidade;
- Bastantes profissionais de TI ainda sentem dificuldade em trabalhar com a clusterização;
- A sua organização de dados só mostrará alguma diferença no final dessa organização, portanto trata-se de um processo mais lento.
Qual a relação entre a clusterização e o aprendizado não supervisionado?
De início pode parecer um pouco confuso, mas a clusterização de dados é totalmente ligada com o aprendizado não supervisionado. Tudo começa com o fato de que, para realizar o agrupamento de dados, não é necessário que esses dados se encontrem pré-rotulados. Já a clusterização tem a capacidade de realizar esse agrupamento de acordo com as características dos dados, sem contar que existem diversas formas para realizar esse cálculo.
Por sua vez, o aprendizado não supervisionado trata-se de uma maneira para fazer com que a máquina aprenda a rotular esses dados por conta própria, o algoritmo encontrado na máquina tem que ter a capacidade para rotular todos esses dados que chegam não organizados.
Quais são os tipos de clusterização?
O principal objetivo de uma clusterização é pegar uma grande quantidade de dados e dividi-los em grupos de modo que cada um deles apresente uma certa semelhança.
Por isso, a clusterização também pode ser categorizada em dois grupos, sendo eles:
Cluster difícil
Trata-se de um Cluster cujos resultados só podem ser agrupados em um único cluster, dado o seu grau de complexidade. Por exemplo: um dado ou um objeto que pertence a um único cluster, ou um grupo de 15 produtos em que cada produto está alocado em um único grupo, consecutivamente.
Cluster flexível
Já o Cluster flexível trata-se da probabilidade do dado ou do objeto estar alocado em algum outro grupo. Ou seja, se você tem um grupo de 15 produtos, existe a probabilidade desse produto pertencer a vários clusters.
Quais os 4 tipos de algoritmos de clusterização?
Quando falamos em clusterização, entendemos que existem várias metodologias que podem ser utilizadas para atingir o objetivo proposto. Sendo assim, cada tipo de algoritmo também possui seu modelo diferente.
Levando em consideração que existe um número muito grande de algoritmos clusterizados, sua utilização ainda acaba sendo pequena. Abaixo, vamos entender os modelos de algoritmos e como eles são utilizados.
Modelos de distribuição
O modelo de distribuição tem como objetivo trabalhar com probabilidades, ou seja um determinado elemento pode pertencer a um determinado grupo ou não. Geralmente esse modelos costumam trabalhar com certas incertezas, sendo assim, fica por conta da pessoa responsável pela clusterização a determinação de qual o grau de precisão desejado.
Modelos centróides
O modelo de modelos centróides, como o próprio nome já diz, utiliza como base a centróide para o posicionamento dos pontos. Com a posição da centróide definida, a pessoa responsável pela clusterização tem uma base central e agrupa os pontos lá. Após isso, posiciona mais uma centróide e posiciona novamente os pontos, assim por diante. Esse modelo é bastante utilizado no algoritmo de K-means.
Modelos de densidade
Esse modelo tem como objetivo trabalhar em cima de gráficos e círculos, ou seja, ele considera a densidade de um certo tamanho do gráfico para realizar a criação de grupos parecidos. Após isso, ele estabelece um círculo e seleciona os elementos que estão dentro do raio, sendo que o raio é um valor que é determinado previamente. A partir disso, o método estabelece mais um círculo e vai selecionando elementos, criando agrupamentos.
Modelos de conectividade
O modelo de conectividade busca trabalhar com a hierarquia de grupo: o modelo de conectividade tem um grupo geral e todos os outros elementos são compostos por grupos menores. De início, esse modelo considera todos os clusters como únicos e, a partir disso, vai agrupando cada um deles com relação à sua distância.
Quais os 5 principais algoritmos de clusterização?
Ao utilizar a clusterização, saber alguns algoritmos para a realização desse processo pode ser de grande valor. Os mais utilizados são os apresentados a seguir.
Clusterização K Means
Para utilizar o algoritmo de clusterização K-Means não é necessário inputs, ou seja ele tem a capacidade de clusterizar os dados de acordo com suas características.
Para iniciar o algoritmo, é necessário selecionar um número de grupos e colocá-los de forma aleatória nos pontos centrais. Para facilitar no momento de definir a quantidade de grupos, é importante analisar os dados e entender quais são os agrupamentos distintos de modo geral.
Cada ponto é calculado de acordo com a distância entre esses pontos e a distância entre cada centro do grupo. Caso o centro esteja mais próximo a um ponto, a classificação muda.
Utilizando esses pontos já classificados, recalculamos o centro do agrupamento pegando a média de todos os vetores desse conjunto. Esse cenário deve ser repetido até que os centros do grupo não mudem muito.
Outra opção é definir centros aleatórios, realizar o cálculo e, ao final, selecionar os pontos que melhor se encaixam com seus resultados.
Clusterização Hierárquica
O Algoritmo de agrupamento hierárquico costuma se dividir em duas categorias, sendo elas a de baixo para cima e a de cima para baixo. Os agrupamentos feitos de baixo para cima, que também são chamados de agrupamento aglomerativo hierárquico, lembram a raiz de uma árvore: um único cluster reúne todas as amostras e faz com que as folhas sejam os clusters, com uma única amostra.
Para iniciar a clusterização hierárquica, devemos começar tratando cada ponto como um único cluster. Sendo assim, se houver 10 pontos de dados, vamos ter 10 clusters diferentes.
Para cada iteração feita, vamos combinar dois clusters em um único, sendo que os dois clusters combinados são classificados como aqueles que possuem uma menor ligação.
Já na finalização do algoritmo, é necessário ir repetindo o processo até que chegue na raiz da árvore, sendo possível enxergar um único cluster com todos os pontos de dados.
Clusterização DBSACAN
Considerado um método baseado no modelo de densidade, o DBSACAN é bastante popular em relação às suas utilizações. Esse método costuma trabalhar com três pontos bem definidos, sendo eles: borda, núcleo e ruído.
Para iniciar a utilização do DBSCAN um ponto de dado deve ser definido, sendo que esses pontos costumam ser pontos não visitados. Após isso, os entornos desse ponto são extraídos, utilizando uma distância épsilon. O Agrupamento só dará início caso existam pontos de dados suficientes dentro dessa área. Se a quantidade não for suficiente, esse ponto é rotulado como um ruído e pode ser deixado de lado. Porém mais para frente pode se tornar parte de um cluster.
Após definido esse primeiro ponto dentro do cluster, o ponto de distância do redor, também chamado de vizinhança, passa a fazer parte desse cluster. O processo de incluir pontos na vizinhança é repetido para todos os novos pontos que estão entrando.
Assim que finalizado o cluster atual, um novo ponto não visitado pode ser recuperado e entrar no processo, fazendo com que a descoberta de novos clusters seja positiva.
Clusterização GMM
O algoritmo GMM parte de um agrupamento baseado em distribuição. Bastante parecido com K-Means, o GMM é utilizado para o encontro de clusters.
Para iniciar a utilização do algoritmo, é necessário selecionar o número de clusters e realizar a distribuição aleatoriamente para cada cluster. Caso deseje ter uma estimativa mais assertiva, primeiro analise seus dados para depois definir os pontos.
Após realizar distribuições gaussianas para cada cluster, você deve realizar o cálculo da probabilidade para que cada determinado dados faça parte de um cluster, sendo que quanto mais esse ponto estiver próximo, maior a probabilidade de ele fazer parte desse cluster.
Com base nessas probabilidades encontradas, realizamos o cálculo de um novo conjunto de parâmetros e podemos observar que cada vez mais os dados vão ser encontrados próximos a essa distribuição feita.
Clusterização de deslocamento médio
O algoritmo de deslocamento médio, por sua vez, é bastante conhecido por procurar janelas deslizantes para poder encontrar áreas densas de pontos de dados — um algoritmo baseado em centróides, assim como o K-Means. Ou seja, seu maior objetivo é encontrar os pontos centrais.
Para iniciarmos, considerando um conjunto de pontos, a janela deslizante, que pode ser chamada de ponto C, deve ser selecionada aleatoriamente. A cada iteração, essa janela deslizante se desloca para uma região que apresenta maior densidade, sendo necessário deslocar o ponto central para a média dos pontos dentro da janela. Esse deslize da janela sempre é feito com base no número de pontos dela.
Após continuar deslocando a janela deslizante, você chegará em um momento em que não será mais possível encontrar uma direção de deslizamento, e que não será mais possível alocar pontos dentro do kernel. Esse processo pode ser repetido diversas vezes e a janela poderá deslizar várias vezes até que os dados possam ser agrupados.
Quais as diferenças entre classificação e clusterização?
Levando em conta que a classificação e a clusterização podem parecer bem semelhantes, ainda existe uma boa diferença entre elas. Quando falamos sobre mineração de dados, as classificações e clusterizações são consideradas dois tipos de aprendizados.
A classificação também pode ser conhecida como uma técnica de rótulo supervisionado, ou seja, a máquina trabalha de acordo com os rótulos já prontos, que já estão classificados, facilitando, então, esse processo.
Já a clusterização é um pouco diferente, por tratar de todo o processo de agrupamento de dados de acordo com suas características e semelhanças e encontrar o ponto de contato entre eles. Para isso, acaba sendo necessário construir suas pré-definições para depois organizá-las.
Outras diferenças entre classificação e clusterização são:
- Objetivos diferentes: a classificação normalmente busca encontrar a qual grupo aquela determinada informação se encaixa, com rótulos já existentes. Já a clusterização preza por organizar as informações de maneira que elas vão se afunilando cada vez mais.
- Nível de complexidade: enquanto a classificação depende de vários processos para depois se classificar, a clusterização está preocupada apenas em agrupar os dados que são semelhantes entre si.
- Algoritmos: a clusterização costuma empregar apenas dois algoritmos, já a categorização apresenta vários algoritmos prováveis para sua utilização.
Quais as principais aplicações da clusterização?
Além de poder ser aplicados em diversas situações, nas empresas a utilização de clusterização pode ser de grande importância quando se fala de organização e praticidade no dia a dia. A clusterização costuma ser utilizadas em diversas situações, sendo algumas delas:
Clientes
A aplicação de clusterização em clientes costuma ser para entender melhor quem são as pessoas que estão envolvidas naquele determinado produto ou organização. Sendo assim, o principal objetivo é extrair informações de cada cliente que sejam relevantes para o negócio.
Um exemplo da criação de cluster nesse cenario seria um agrupamento de pessoas do sexo feminino, um agrupamento do sexo masculino, um agrupamento por faixa-etaria, etc. Desse modo, os dados podem se tornar bastante relevantes de acordo com a necessidade da empresa para realizar ações de marketing mais eficientes e pensar em melhorias no produto.
Produtos
O Cluster focado em produto, bem parecido com o cluster focado no cliente, tem como objetivo focar no agrupamento dos produtos para a organização de estoques, por exemplo.
Supondo que uma empresa de material de construção deseje organizar seu estoque, será necessário realizar um agrupamento de produtos, sejam eles por cor, tipo, tamanho entre outras categorias para que, no final, a organização fique mais simples.
Servidores
Um pouco diferente das ideias de clusterização de produto e cliente, a clusterização de servidores entende que cada computador que está conectado a um servidor pode ser considerado um nó.
A clusterização de servidores costuma ser utilizado empresas que apresentam computação em nuvem (cloud computing).
Dados
A clusterização de dados trata-se de uma forma totalmente voltada para empresas com a intenção de trazer mais facilidade e organização dentro de um processo. Ela tem como objetivo visar toda a praticidade em consultas futuras dentro de uma empresa, por exemplo.
Ao clusterizar milhares de dados e informações de uma empresa, gera-se mais agilidade e precisão.
Conclusão
O processo de clusterização de dados dentro de uma empresa ou até mesmo pessoal está se tornando cada vez mais fundamental. Sendo assim, se aprofundar cada vez mais e ter mais conhecimento sobre esse modelo é de grande importância.
Se esse assunto e a aplicação práticas dessas tecnologias e conhecimentos ainda não ficam tão claros para você, te convido a ler nosso artigo sobre como a inteligência artificial pode auxiliar no diagnóstico de câncer.


