Banco de dados relacional… Talvez esse não seja um assunto novo para você, e pode ser até um tema comum do seu dia a dia.
Os bancos de dados relacionais, apesar de serem um tema levemente negligenciado por algumas pessoas, é muito importante sua compreensão, uma vez que é essencial no dia a dia de toda pessoa programadora entender as suas conexões com o banco, os tipos de banco que existem e como escolher o mais adequado no desenvolvimento das suas aplicações.
Caso não conheça acerca do tema, fique tranquilo, pois aqui detalharemos as principais características de um banco de dados relacional, mostraremos exemplos de CRUD, e maneiras para construir o seu primeiro banco.
Nesse post você verá:
- O que é um banco de dados relacional e para que serve?
- Como funcionam os bancos de dados relacionais? Entenda a estrutura e elementos!
- Quais os tipos de relacionamentos entre bancos de dados?
- Os bancos de dados autônomos são o futuro dos bancos de dados relacionais?
- Encapsulamento e os bancos de dados relacionais
- Quais as principais funcionalidades dos SGBDRs?
- Banco de dados relacional: vantagens e desvantagens!
- Banco de dados relacional vs não relacional: diferenças e qual o melhor para você?
- Como criar um banco de dados?
O que é um banco de dados relacional e para que serve?
Um banco de dados relacional é um tipo de banco de dados — sim, existem outros tipos de banco, como os não relacionais, mas não nos aprofundaremos neste assunto no momento. Logo, os bancos de dados relacionais são feitos com base no modelo relacional de organização para representar e organizar dados em tabelas.
Nesse sentido, podemos ter acesso a diferentes tipos de dados, como os dados financeiros de uma empresa, as informações de pacientes em um hospital, estudantes de uma universidade etc.
Além disso, quando nos referimos a essa estrutura do modelo relacional, nesse tipo de banco de dados cada linha na tabela representará uma ID única, que chamaremos de chave. Somado-se a isso, vale ressaltar outras características que fazem parte do modelo de banco de dados relacional como as colunas, as quais contêm atributos de cada dado e podem também ter um valor.
Tudo isso auxilia na construção de relações que interligam a estrutura de dados em um banco. Mas, talvez você esteja se perguntando qual a utilidade de um banco de dados relacional.
Quando temos informações, para podermos entender de forma eficiente, é necessário organizá-las. Dessa forma, um banco de dados relacional é importante à medida que surge a necessidade de organização dos seus dados. Além disso, também permite a otimização do trabalho, uma vez que diversas pessoas podem acessar simultaneamente e há uma maior segurança no processo de armazenamento.
Grande parte dos bancos de dados relacionais utilizam a linguagem de programação estruturada especializada para sistemas de banco de dados, o SQL.
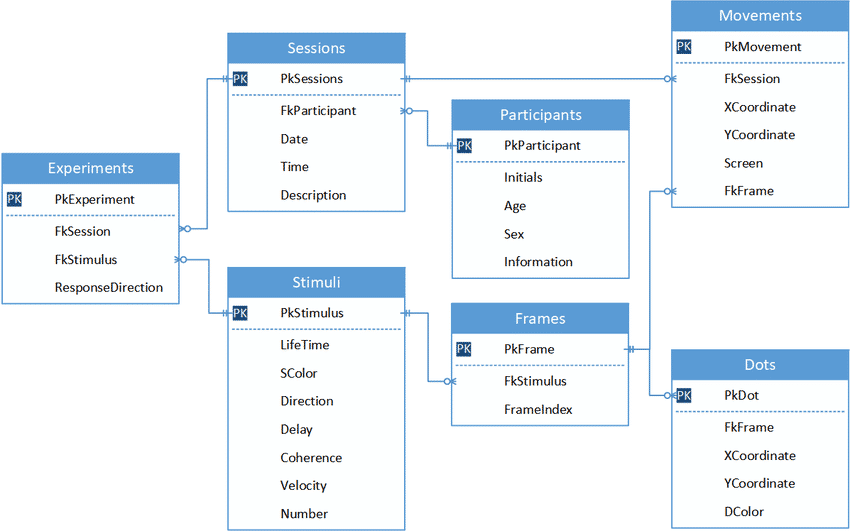
Como funcionam os bancos de dados relacionais? Entenda a estrutura e elementos!
Para construir um banco de dados temos diferentes tipos de objetivos que fazem parte. Entre eles:
Tabela: é responsável por armazenar os dados, como por exemplo o nome e a idade das pessoas estudantes do curso de Ciência da Computação de determinada universidade. A tabela também pode ser chamada de relação, uma vez que um banco de dados relacional pode ter uma ou mais relações.
Coluna: é responsável por armazenar apenas um tipo específico de dado, podendo ele ser nulo ou não. É importante lembrar que pode ser uma coluna não-chave, ou seja, o tipo de dado pode se repetir em outras colunas.
Tupla: é responsável por representar cada registro de um determinado dado. O registro é identificado por uma chave primária, uma vez que não é possível ter registros duplicados.
Relacionamento: atente-se a essa parte, a relação é diferente de relacionamento. Uma vez que a Relação representará a tabela, o relacionamento será a associação entre elas, visto que estão conectadas por chaves primárias e por chaves estrangeiras.
Chave Primária: do inglês “primary key” e apelidado carinhosamente como “pk”, a chave primária é um atributo (ou coluna) que identifica um registro de forma única. A exemplo disso, temos o CPF de terminada pessoa estudante.
Chave Estrangeira: também chamada de “foreign key” ou “fk”, é um atributo que designará a forma que as tabelas se relacionam entre si. Ou seja, uma fk faz relação a uma pk. A exemplo disso, podemos relacionar a tabela “gostos musicais”, por meio de uma chave estrangeira, que fará o relacionamento com a chave primária na relação de estudantes.
Quais os tipos de relacionamentos entre bancos de dados?
Já definimos de forma breve o conceito de relacionamentos de um banco de dados relacional e agora vamos abordar os tipos de relacionamentos existentes entre os bancos de dados:
Um para um: quando nos referimos a esse tipo de relacionamento, estamos dizendo que um registro em uma tabela está ligado a apenas um registro em outra tabela/relação. Para exemplificar a situação, podemos utilizar ainda estudantes do curso de Ciência da Computação, cada estudante tem um ID exclusivo e cada ID é atribuído a apenas uma pessoa.
Um para muitos: aqui estamos falando que a tabela de chave primária pode se relacionar com nenhum, com um ou muitos registros da tabela que está sendo associada.
Muitos para muitos: dado as definições anteriores, esse tipo de relacionamento pode se relacionar a nenhum ou a vários registros em outra tabela. Aqui, nesse tipo de relacionamento é necessário uma terceira relação/tabela.
Os bancos de dados autônomos são o futuro dos bancos de dados relacionais?
Um banco de dados autônomo é uma IA em nuvem responsável por automatizar e ajustar um banco de dados.Todas as tarefas que são feitas por DBAs em bancos relacionais, como administrar a segurança, realizar backups e executar atualizações rotineiras no gerenciamento do banco, entre outras.
Atualmente, a sua utilização tem sido cada vez mais frequente, dado o volume de dados que é gerado a todo momento de forma descontrolada.
Nesse sentido, vemos que o advento do Big Data acelerou a necessidade de utilização de bancos automatizados. Além disso, existem outros benefícios quando falamos em um banco de dados automatizado, entre eles podemos citar:
- Melhor desempenho e segurança, uma vez que em bancos de dados relacionais é feita a aplicação de patch manualmente, o que o torna fraco e pode até eliminar completamente a sua proteção de segurança. Logo, em um banco automatizado, os patches não precisam sofrer alterações manuais, o que diminui o risco de enfraquecimento do sistema.
- A eliminação de tarefas manuais também é importante, uma vez que auxilia a automatização e foco da pessoa desenvolvedora em outras atividades, como a extração de insights, otimizando o fluxo de trabalho.
Com a velocidade na geração de dados e a necessidade de geração de análises, os bancos de dados autônomos são recursos inteligentes para o dia a dia, oferecendo muitas vantagens para as empresas. Nesse sentido, empresas podem migrar cada vez mais para utilização desse tipo de banco de dados, uma vez que reduz custos e auxilia profissionais a atuarem em áreas de inovação dentro dos projetos.
Acoplamento e os bancos de dados relacionais
Primeiramente, vamos tentar definir o que é acoplamento no seu banco de dados relacional. Quando nos referimos a acoplamento, estamos falando de níveis de dependência entre dois itens. Infelizmente, nem sempre é interessante ter um banco tão acoplado, visto que torna difícil a manutenção e evolução dele.
Além disso, no processo de refatoração de um banco de dados, ou seja, uma técnica focada na recodificação/ alteração do código, poderá haver problemas no banco ou em diferentes aplicações que estão acopladas. Nesse sentido, vale destacar que os bancos de dados relacionais podem estar acoplados para diferentes fins, entre eles:
- Documentação: refere-se a quando esse sistema de banco muda, logo a documentação também deve ser alterada.
- Scripts para migração de dados: refere-se às mudanças de script que requerem migração.
- O código fonte da aplicação: refere-se às alterações ocorridas no código fonte da aplicação que quando alterada o esquema também precisa ser modificado.
- O código fonte para extração de dados: refere-se a scripts e/ou programas de extração de dados, muitas vezes responsáveis por gerar arquivos em XML ou por carregar dados em outro banco.
Encapsulamento e os bancos de dados relacionais
Já imaginou como ocorrem os procedimentos de rastreamento em banco de dados sem que interfira na usabilidade da pessoa desenvolvedora durante o seu acesso ao banco de dados? Tudo isso é possível graças ao processo de encapsulamento.
O encapsulamento é um meio para a implementação de alterações de modo “invisível”, no qual é possível fazer modificações dentro do banco sem modificar outros sistemas — diferente do acoplamento, em que qualquer alteração precisaria de um conjunto de alterações dentro do banco de dados.
Somado a isso, outro ponto interessante é o fato dos DBAs poderem trabalhar de forma livre em suas estratégias na usabilidade do banco sem que afete uma gama de outras implementações que estão sendo desenvolvidas por outros times.
Logo, as pessoas programadoras podem focar apenas na resolução dos seus problemas de implementações sem precisarem estar focados no banco de dados. Ou seja, tudo isso promove maior liberdade a profissionais. Infelizmente, nem sempre é possível não utilizar o acoplamento, mas a estratégia de encapsulamento é bastante útil quando cabível na atividade em questão.
Desse modo, existem também desvantagens, como a incompatibilidade entre plataformas/sistemas. No entanto, enquanto pudermos reduzir o acoplamento teremos vantagens, uma vez que está diretamente ligado também a redução de trabalho e consequentemente de custos.
Como escolher o seu banco de dados relacional (SGBDRs)?
Um SGBDRs é um sistema que armazena, organiza, recupera, consulta, gerencia e recupera dados de maneira organizada. O SGBDRs possui uma interface gráfica que auxilia as pessoas usuárias a utilizarem os seus recursos de maneira um pouco mais funcional, uma vez que também ajuda na execução de tarefas de gerenciamento administrativas e no seu desempenho.
Nesse sentido, é essencial ter um banco de dados seguro e que atenda as necessidades do seu problema. Aqui listamos alguns pontos que poderão auxiliá-lo nesse processo de escolha:
- Necessidades de desempenho e confiabilidade: já falamos sobre a importância de ter um sistema seguro nesse mesmo tópico, logo, a confiabilidade e proteção dos nossos dados torna-se essencial nesse processo de decisão. Além disso, o desempenho desse sistema precisará suportar grandes volumes de dados para que funcione de maneira rápida e eficaz? Então, esse será um ponto relevante nessa tomada de decisão.
- Simultaneidade: se esse banco for utilizado por um grande número de usuários e conectado a diferentes aplicativos é importante saber quanto aquele sistema é capaz de suportar para que não atrapalhe no desempenho do seu produto.
- Escalabilidade: quando nos referimos a escalabilidade precisamos entender sobre a base de dados que estamos lidando, caso seja um volume muito grande, existirá, certamente um produto que nos auxilie melhor nessa questão.
Quais as principais funcionalidades dos SGBDRs?
Nos SGBDRs, existe uma linguagem própria para a manipulação dessa gama de dados existente. Entre elas, existe o CRUD, sigla inglesa para CREATE, READ, UPDATE E DELETE. Tal qual é uma funcionalidade básica da linguagem. Agora, vamos criar uma implementação básica para que você possa assimilar como isso funcionaria na prática:
Vamos supor que Maria tem uma mercearia e quer inserir os novos produtos que chegaram para a venda em seu banco de dados.
1. Declarando a inserção de uma linha na tabela Mercearia
INSERT INTO MERCEARIA
(idFrutas, idPerfumes, IdHigiene)
VALUES(3232389,128128, 4)2. Consultando uma linha na tabela Mercearia
SELECT * FROM Mercearia WHERE MERC_ID = 128223. Atualizando uma linha na tabela Mercearia
UPDATE Mercearia
SET idFrutas = 'FFG129302', numeroFruta = 32
WHERE idMerc = 128224. Declaração para excluir linha na tabela Mercearia
DELETE FROM Mercearia
WHERE idMerc > 12822 AND idFrutas = 'FIWN22222'
Banco de dados relacional: vantagens e desvantagens!
- Vantagens: quando falamos de banco de dados relacionais, estamos falando de maneiras de organizar de forma clara as nossas informações. Logo, já imaginou ter que lidar com inúmeras fontes de informação sem o auxílio dessa tecnologia? Parece impossível, não é mesmo? Mas bem, no passado funcionava assim, porém, hoje em dia — graças aos bancos de dados relacionais — podemos ter esses dados tabulados de maneira organizada, otimizando assim as nossas atividades.
- Desvantagens: No entanto, você já imaginou o trabalho que deve dar na hora de criar esses sistemas? Então, é nesse ponto que surge um dos maiores problemas, pois criar um banco de dados relacional é complexo. Nesse sentido, a criação de relacionamentos, a definição das chaves e as conexões entre tabelas tornam esse processo complicado.
Banco de dados relacional vs não relacional: diferenças e qual o melhor para você?
Já definimos ao longo de todo texto do que se trata um banco de dados relacional, ou seja, ele basicamente é responsável por armazenar e organizar fontes de dados relacionando-as entre si. Mas, agora falaremos do que se trata um banco de dados não relacional.
Nesse sentido, quando nos referimos a um banco de dados não relacional estamos falando de qualquer banco que não segue o padrão SGBDR, logo, são conhecidos por fazerem parte do sistema NoSQL. Entre eles, existem os mais populares, como o MongoDB, Cassandra e o Redis.
Para escolher o melhor banco de dados, seja relacional ou não relacional, precisamos definir qual a finalidade e o tipo de dado com o qual estamos trabalhando, uma vez que isso determinará a usabilidade dos dados. Dessa forma, caso você por exemplo, esteja trabalhando com Big Data e fontes de dados do tipo JSON, o ideal será utilizar um banco de dados não relacional, uma vez que ele foi desenvolvido para manipular esse tipo de dado.
Como criar um banco de dados?
Para desenvolver um projeto precisaremos dividi-lo em três partes, que são: projeto conceitual, projeto lógico e projeto físico.
Projeto conceitual: refere-se ao momento de alinhamento acerca das expectativas e necessidades de clientes com a pessoa desenvolvedora, na qual é elaborada uma visão macro do projeto.
Projeto lógico: refere-se ao momento de detalhamento das necessidades e conceitos com o projeto para a sua organização, na qual são esquematizadas as tabelas, os metadados das colunas, etc.
Projeto físico: refere-se ao momento que ocorre o detalhamento técnico para a implementação do banco de dados, na qual definem-se questões como as formas de armazenamento, scripts e outros.
Espero que, se você já conhecia sobre banco de dados relacionais, esse texto tenha sido uma forma de aprofundar os seus conhecimentos na área. E para você que ainda não tinha familiaridade esse texto tenha se tornado enriquecedor no aprimoramento do seu desenvolvimento intelectual.
Nesse sentido, vimos que uma estrutura de banco de dados é essencial para gerir os nossos dados. Sejamos pessoas desenvolvedoras de software ou pessoas cientistas de dados, é importante conhecer e ter familiaridade com o conceito de banco de dados e o que ele representa para as suas aplicações.
Gostou desse conteúdo? Então vem aprender um pouco sobre PL/SQL, o que é e como usar!


