
PL/SQL é uma linguagem de consulta estruturada que utiliza a linguagem de banco SQL, No PL/SQL, temos a adição de muitas construções procedurais à linguagem SQL para ajudar a superar algumas limitações da linguagem. Além do que, o PL/SQL oferece uma solução de linguagem de programação mais abrangente para resolver problemas de aplicativos que utilizam o banco de dados Oracle.
PL/SQL é uma linguagem muito robusta e legível, foi construída para expressar da melhor maneira possível o seu código. Além disso, é uma linguagem simples de aprender.
Ao longo do texto veremos tudo sobre o PL/SQL, tanto a sua história como suas principais características, continue lendo com a gente!
- O que é PL/SQL?
- Para que serve e quando usar o PL/SQL?
- Quais as diferenças entre SQL e PL/SQL?
- Quais as vantagens e desvantagens do PL/SQL?
- Entenda a arquitetura do PL/SQL
- Tipos de dados
- Variáveis
- Operadores
- Cursores
- Sequence
- Estruturas condicionais
- Funções
- Procedures
- Triggers
- JOBs
- Views
- Ambiente de execução do PLSQL
- Desenvolvedor PL/SQL: o que faz, salário e carreira!
O que é PL/SQL?
PL/SQL é uma extensão da linguagem SQL baseado no banco de dados Oracle. Nessa ferramenta, temos a combinação do poder de manipulação dos dados do SQL com o poder de processamento da linguagem procedural para criar consultas SQL poderosíssimas. A PL/SQL ainda oferece o processamento contínuo de instruções SQL, aprimorando a segurança, a portabilidade e a robustez do banco de dados.
Basicamente, PL/SQL instrui o compilador “o que fazer” por meio do SQL e “como fazer” por meio de sua lógica procedimental. Parecido com outras linguagens de banco de dados, dá mais controle aos programadores e programadoras pelo uso de loops, condições e conceitos orientados a objeto. O significado completo de PL/SQL é Procedural Language/Structured Query Language.
Para que serve e quando usar o PL/SQL?
Conseguimos utilizar o PL/SQL para escrever programas que ficam armazenados no nosso banco de dados e que podem ser executados por alguma aplicação ou usuário que acesse o banco. Devemos compreender que essa ferramenta não se limita a apenas processar instruções SQL (INSERT, DELETE, SELECT e UPDATE) para o banco, e sim, executar tarefas que exigem uma série de estruturas de decisão, como loops e coisas parecidas.
Dessa forma, temos um grande mar de possibilidades e não devemos nos esquecer que, como qualquer outra linguagem, é provável que exista código bom ou ruim. Para não cometer esses equívocos, é recomendado entender muito bem a estrutura do código PL/SQL, os seus mínimos detalhes da sua implementação e como funciona a sua interação com o código SQL.
Quais as diferenças entre SQL e PL/SQL?
| SQL | PL/SQL |
| Apenas executa uma consulta de operações DML e DDL. | Usado para escrever blocos de códigos para um programa, procedure, função, etc |
| SQL é declarativo, definindo o que precisa ser feito, ao invés de como as coisas precisam ser feitas. | PL/SQL é procedural e define como as coisas precisam ser feitas. |
| Execute como uma única instrução. | Execute como um bloco inteiro. |
| Usado principalmente para a manipulação de dados. | Usado para criar um aplicativo, site, etc. |
| Interação com um servidor de banco de dados. | Sem interação com o servidor de banco de dados. |
| Não deve conter código PL/SQL. | É uma extensão do SQL, logo pode conter SQL dentro dele. |
Quais as vantagens e desvantagens do PL/SQL?
Vantagens
- Desempenho elevado, já que o SQL é executado de forma agrupada, ao invés de uma única instrução.
- Alta produtividade.
- Integração total com SQL
- Portabilidade total
- Muita segurança.
- Suporte aos conceitos de POO
- Escalabilidade e fácil de gerenciar
- Também oferece suporte ao desenvolvimento de aplicativos da web.
Desvantagens
- As procedures que ficam guardadas no PL/SQL usam muita memória.
- Não oferece suporte ao debugging de procedures armazenadas.
- Qualquer mudança que ocorra no banco de dados requer alguma mudança na camada de apresentação.
- Acaba não separando as funções do desenvolvedor back-end e front-end.
- É complicado separar o desenvolvimento HTML do desenvolvimento PL/SQL.
Entenda a arquitetura do PL/SQL
A arquitetura do PL/SQL pode ser representada da seguinte forma:

A arquitetura PL / SQL consiste principalmente nesses três componentes:
- Bloco do PL/SQL
- Motor do PL/SQL
- Servidor do banco de dados
Bloco do PL/SQL
Esse é o componente onde colocaremos o nosso código PL/SQL. Ele consiste de diversas seções para dividir o código logicamente (seção declarativa para as declarações, seção de execução para instruções de processamento, seção de tratamento de exceções para tratamento de erros).
Além do mais, também contém a instrução SQL que interage com o servidor de banco de dados, todas as suas unidades Pl/SQL são tratadas como blocos PL/SQL e esse é o estágio inicial da arquitetura que serve como a entrada principal.
A seguir temos alguns tipos de unidades PL/SQL:
- Anonymous Block
- Function
- Library
- Procedure
- Package Body
- Package Specification
- Trigger
- Type
- Type Body
Motor do PL/SQL
O motor do PL/SQL é o componente onde há o processamento real dos códigos. Ele separa as unidades PL/SQL da parte de entrada do SQL (conforme mostrado anteriormente pela imagem). As unidades separadas do PL/SQL são gerenciadas pelo próprio motor. A parte do SQL é enviada para o servidor para fazer a interação real com o banco de dados. Ele pode ser instalado tanto no servidor de banco de dados como no servidor de aplicativos.
Servidor do banco de dados
Esse é o principal componente da unidade PL/SQL. Nele, possuímos o armazenamento dos dados. O motor do PL/SQL usa o SQL da unidade PL/SQL para interagir com o servidor de banco de dados. Por fim, o executor do SQL é o responsável por analisar todas as instruções SQL de entrada e fazer as devidas execuções.
Tipos de dados
Como qualquer outra linguagem de programação, o PL/SQL também tem os seus tipos de dados que podem ser usados em variáveis, constantes e parâmetros. Na tabela a seguir podemos ver as principais categorias de tipos de dados:
| Scalar | Valores únicos que não utilizam nenhum componente, como NUMBER, DATE e BOOLEAN. |
| Large Object (LOB) | É um referenciador de objetos grandes que são guardados separadamente dos itens de dados, texto, imagens gráficas, vídeos são exemplos disso. |
| Composite | Dentro do Composite existem os componentes que podem ser manipulados individualmente, como os elementos de uma matriz, registro ou tabela. |
| Reference | Basicamente, serve para referenciar outros itens de dados. |
Variáveis
Podemos dizer que uma variável nada mais é do que um nome dado a um espaço de armazenamento que nossos aplicativos podem manipular. Como já vimos, cada variável no PL/SQL tem um tipo de dado específico, que determina seu tamanho e o layout da memória. Além do mais, podemos designar a faixa de valores que podem ser armazenados nessa memória e também o conjunto de operações que podem ser realizadas à variável.
O nome de uma variável no PL/SQL consiste em uma letra seguida opcionalmente por mais letras, números, cifrões, sublinhados e sinais numéricos. Tudo isso não pode ultrapassar 30 caracteres. Por default, os nomes das variáveis não diferenciam maiúsculas de minúsculas. Também não podemos esquecer que não é possível utilizar uma palavra-chave reservada do PL/SQL como um nome de variável.
Por fim, as variáveis do PL/SQL devem ser declaradas na seção de declaração ou em um pacote como uma variável global. Quando você declara uma variável, o PL/SQL aloca memória para o valor da variável e o local de armazenamento é identificado pelo da variável.
Operadores
Um operador é um símbolo que informa ao compilador que ele deve executar uma manipulação lógica ou matemática específica. Na linguagem PL/SQL temos uma série de operadores integrados que oferecem um amplo suporte a linguagem, alguns deles são:
- Operadores aritméticos
- Operadores relacionais
- Operadores de comparação
- Operadores lógicos
- Operadores de texto
Com esses operadores conseguimos executar tarefas como soma, multiplicação, comparação entre o dados e muito mais!
Cursores
No Oracle, temos uma área de memória conhecida como área de contexto. Nela, as instruções SQL são processadas e ela contém todas as informações necessárias para o processamento da instrução, como por exemplo, o número de linhas processadas.
Dessa forma, temos que um cursor é um ponteiro para esta área de contexto. A linguagem PL/SQL controla toda a área de contexto a partir de um cursor. Um cursor tem o valor das linhas retornadas por uma instrução SQL. Esse conjunto de linhas que o cursor mantém é referido como o conjunto ativo.
Você pode nomear um cursor para que ele possa ser referido em um programa para procurar e processar as linhas retornadas por uma instrução SQL, uma por uma. Existem dois tipos de cursores:
- Cursores implícitos
- Cursores explícitos
Sequence
Sequence é um objeto do banco de dados que pode ser criado por um usuário e compartilhado para vários usuários.
Conseguimos utilizar as Sequences para a criação de valor para uma chave primária onde o valor deve ser único por linha. Os números das sequências são armazenados e gerados independentemente das tabelas, logo a mesma Sequence consegue ser utilizada em várias tabelas diferentes.
Sintaxe de uma sequence:
CREATE SEQUENCE sequence
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}]
[{CACHE n | NOCACHE}]
[{ORDER | NOORDER}];Exemplo de uso:
CREATE SEQUENCE ID_TESTE
INCREMENT BY 1
START WITH 10
MAXVALUE 5000
NOCACHE
NOCYCLE;Com a criação de uma id incremental conseguimos inserir novos dados, o formato do Insert deve ser assim:
--inseri os dados da tabela Teste
INSERT INTO TESTE(idteste, valor)
VALUES(ID_TESTE.NEXTVAL,'TESTE SEQUENCE');
--aciona o proximo valor da sequenciaEstruturas condicionais
Como qualquer outra linguagem, o PL/SQL também tem estruturas condicionais:
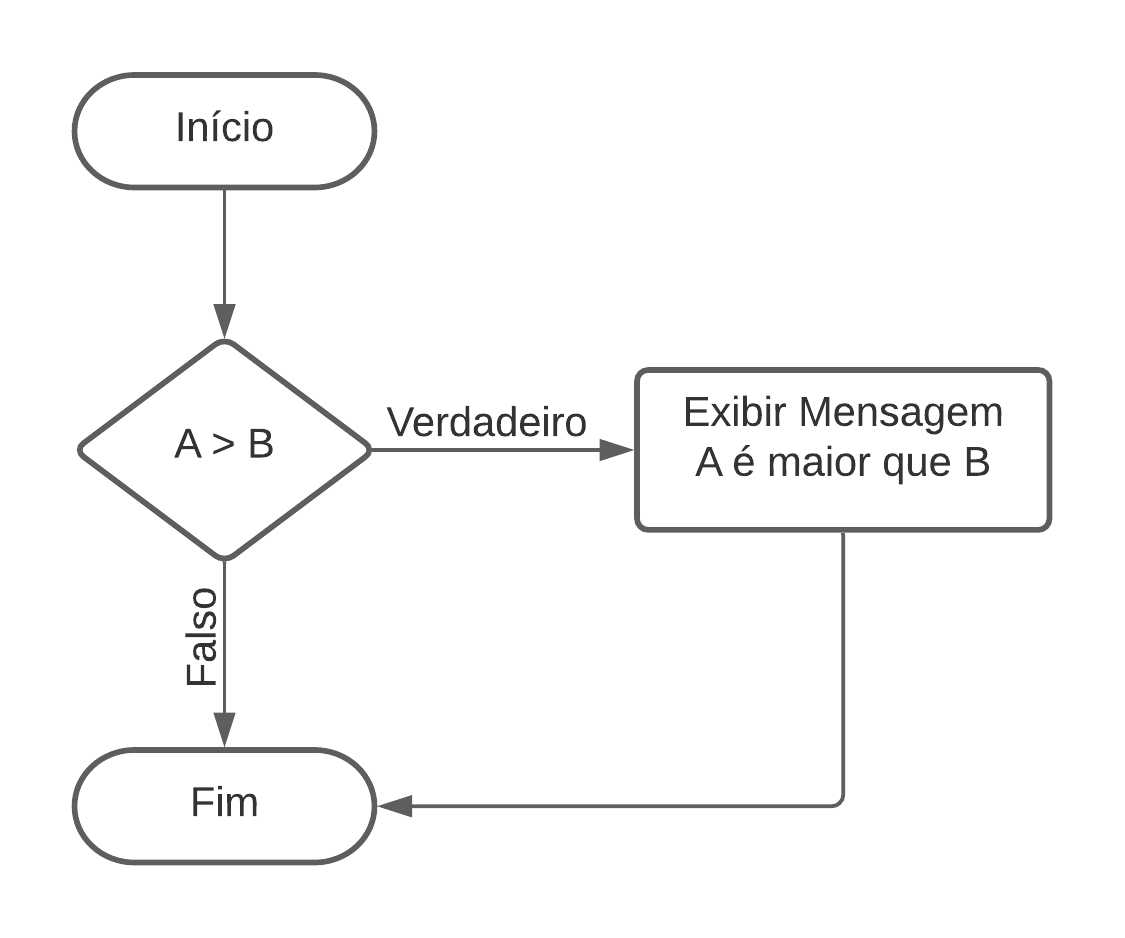
Um exemplo disso:
-- Exibe o numero par ou impar
DECLARE
numero INTEGER;
BEGIN
numero:=1;
if(cnumero mod 2 = 0) then -- Par
DBMS_OUTPUT.PUT_LINE('par');
else -- Impar
DBMS_OUTPUT.PUT_LINE('impar');
end if;
END;Utilizando a expressão Case:
CASE [ expressão ]
WHEN condicao THEN resultado
WHEN condicao_2 THEN resultado_2
...
WHEN condicao_n THEN resultado_n
ENDFunções
Uma função é um bloco de código que, a partir de uma lógica pré-definida, retorna um valor. Logo abaixo veremos como criar e chamar as funções no PL/SQL!
Criando uma função
Uma função sozinha é criada utilizando a instrução CREATE FUNCTION. A sintaxe simplificada para a instrução CREATE OR REPLACE PROCEDURE é a seguinte:
CREATE [OR REPLACE] FUNCTION nome_da_funcao
[(nome_do_parametro [IN | OUT | IN OUT] type [, ...])]
RETURN tipo_do_dado_de_retorno
{IS | AS}
BEGIN
< corpo_da_funcao >
END [nome_da_funcao];Nesse código temos:
- A variável nome_da_funcao que especifica o nome da função.
- A opção [OR REPLACE] que permite a modificação de uma função existente.
- A lista de parâmetros opcionais contém o nome, modo e tipo dos parâmetros. IN representa os valores que vão ser passados de fora e OUT significa que os parâmetros vão ser usados para retornar um valor fora da procedure.
- A função deve conter um retorno.
- A palavra RETURN especifica o tipo de dados que você retornará na função.
- No corpo_da_função temos a parte executável.
- A palavra-chave AS é usada ao invés do IS para criar uma função standalone.
Exemplo:
O exemplo a seguir ilustra como criar e chamar uma função standalone. Nesta função, temos o retorno do número total de clientes na tabela de clientes:
Select * from clientes;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+
CREATE OR REPLACE FUNCTION totalClientes
RETURN number IS
total number(2) := 0;
BEGIN
SELECT count(*) into total
FROM clientes;
RETURN total;
END;
/ Se você executar o código acima na linha de comando do SQL, provavelmente será bem sucedido.
Chamando uma função
Na criação de uma função definimos o que ela deve fazer. Para utilizar uma função, devemos chamá-la para executar a tarefa atribuída. Quando o programa chama uma função, o controle do programa é passado para a função chamada.
Uma função chamada executa a tarefa definida e quando sua instrução de retorno é executada ou quando a instrução final é alcançada, ela retorna o controle ao programa principal.
Para chamarmos uma função, precisamos passar os parâmetros necessários junto com o nome da função e, se a função retornar um valor, você consegue armazenar o valor retornado. No código a seguir chamamos a função totalClientes de um bloco anônimo:
DECLARE
c number(2);
BEGIN
c := totalClientes();
dbms_output.put_line('Total númerico de clientes: ' || c);
END;
/
-- Resultado:
-- Total númerico de clientes: 6
-- PL/SQL procedure successfully completed. Exemplo:
No próximo exemplo criamos e executamos uma função que retorna o maior valor entre dois números utilizando toda a lógica do PL/SQL.
DECLARE
a number;
b number;
c number;
FUNCTION findMax(x IN number, y IN number)
RETURN number
IS
z number;
BEGIN
IF x > y THEN
z:= x;
ELSE
Z:= y;
END IF;
RETURN z;
END;
BEGIN
a:= 36;
b:= 48;
c := findMax(a, b);
dbms_output.put_line(' Máximo de (36, 48): ' || c);
END;
/ O resultado dessa operação será 48!
Procedures
Uma procedure é uma unidade/módulo de um programa que executa uma tarefa bem específica. Esses subprogramas, como são chamadas as procedures, são combinados para formar programas maiores. Isso é basicamente chamado de design modular. Um subprograma pode ser invocado por outro subprograma ou programa, no qual é denominado calling program.
Um subprograma pode ser criado no nível de schema, dentro de um package ou de um bloco PL/SQL.
No nível de schema, o subprograma é um subprograma standalone. Ele é criado a partir da instrução CREATE PROCEDURE ou CREATE FUNCTION. Ele é armazenado no banco de dados e pode ser excluído com a instrução DROP PROCEDURE ou DROP FUNCTION.
Um subprograma criado dentro de um package é um subprograma empacotado. Ele também é armazenado no banco de dados e pode ser excluído apenas quando o pacote é excluído com a instrução DROP PACKAGE.
Os subprogramas PL/SQL são chamados de blocos PL/SQL que também podem ser chamados com um conjunto de parâmetros. PL/SQL fornece dois tipos de subprogramas:
- Funções – Nesses subprogramas temos o retorno de apenas um valor. É usado principalmente para calcular e retornar um valor simples.
- Procedures – Esses subprogramas não retornam um valor diretamente. Usado para executar uma ação.
Criando uma Procedure
Primeiramente devemos entender como é estruturado o bloco da procedure no PL/SQL. Essa estrutura é dividida em três partes, como podemos ver a seguir:
| Parte declarativa | É uma parte opcional. No entanto, a parte declarativa de um subprograma não começa com a palavra-chave DECLARE. Ele contém declarações de tipos, cursores, constantes, variáveis, exceções e subprogramas aninhados. Esses itens são locais para o subprograma e deixam de existir quando o subprograma conclui a execução. |
| Parte executável | Esta é uma parte obrigatória e contém instruções que executam a ação designada. |
| Manipulação de exceção | Esta é novamente uma parte opcional. Ele contém o código que trata os erros de tempo de execução. |
Com isso em mente, vamos continuar a criação da nossa procedure.
A sintaxe simplificada para criar uma procedure é a seguinte:
CREATE [OR REPLACE] PROCEDURE nome_da_procedure
[(nome_do_parametro [IN | OUT | IN OUT] type [, ...])]
{IS | AS}
BEGIN
< corpo_da_procedure >
END nome_da_procedure; Onde temos que:
- nome_da_procedure é onde especificamos o nome da Procedure.
- A opção [OR REPLACE] permite a modificação de uma procedure existente.
- A lista de parâmetros opcional contém nome, modo e tipos de parâmetros. IN representa o valor que será passado de fora e OUT representa o parâmetro que será usado para retornar um valor fora da procedure.
- No corpo_da_procedure temos a parte executável.
- A palavra-chave AS é usada em vez da palavra-chave IS para criar uma procedure standalone.
Exemplo:
O exemplo a seguir mostra uma simples procedure que exibe a famosa mensagem Hello World quando é chamada:
CREATE OR REPLACE PROCEDURE hello_world
AS
BEGIN
dbms_output.put_line('Olá mundo da Trybe!');
END;
/Chamando uma Procedure
Uma Procedure pode ser chamada de duas maneiras, usando a palavra-chave EXECUTE ou chamado o nome da procedure em um bloco PL/SQL.
Executando a partir do comando:
EXECUTE hello_world ;A partir de um bloco PL/SQL:
BEGIN
hello_world;
END;
/Nos dois casos temos o resultado da nossa procedure que criamos.
Deletando uma Procedure
Para deletar uma procedure é bem simples, apenas utilize o comando DROP PROCEDURE. A sintaxe fica dessa forma:
DROP PROCEDURE nome_da_procedure; Triggers
Os Triggers são programas armazenados que são executados ou disparados automaticamente quando ocorrem alguns eventos. Os Triggers são, na verdade, escritos para serem executados em resposta a qualquer um dos seguintes eventos:
- Uma instrução que manipula o banco de dados (DML) (DELETE, INSERT ou UPDATE)
- Uma instrução de definição de banco de dados (DDL) (CREATE, ALTER ou DROP)
- Ou uma operação no banco de dados (SERVERERROR, LOGON, LOGOFF, STARTUP ou SHUTDOWN)
Os Triggers podem ser definidos na tabela, view, schema ou banco de dados ao qual o evento está associado.
As principais vantagens de se utilizar os Triggers são:
- Geração automática de algum valor para alguma tabela
- Registro de eventos e armazenamento de informações sobre o acesso ao banco de dados.
- Replicação síncrona das tabelas
- Autorizações de segurança
- Prevenção de transações inválidas.
Criando uma Trigger
A sintaxe de criação de uma trigger é a seguinte:
CREATE [OR REPLACE ] TRIGGER nome_da_trigger
{BEFORE | AFTER | INSTEAD OF }
{INSERT [OR] | UPDATE [OR] | DELETE}
[OF nome_da_coluna]
ON nome_da_tabela
[REFERENCING OLD AS o NEW AS n]
[FOR EACH ROW]
WHEN (condição)
DECLARE
Manipulação de declarações
BEGIN
Manipulação de execuções
EXCEPTION
Manipulação de exceção
END; No código temos:
- CREATE [OR REPLACE] TRIGGER nome_da_trigger – Cria ou substitui uma Trigger existente pelo nome_da_trigger.
- {BEFORE | AFTER | INSTEAD OF} – Especifica quando o gatilho será executado. A palavra INSTEAD OF é usada para criar gatilhos em uma View.
- {INSERT [OR] | UPDATE [OR] | DELETE} – Aqui especificamos a operação DML.
- [OF nome_da_coluna] – Nome da coluna que será atualizado.
- [ON nome_da_tabela] – Especifica o nome da tabela associada a Trigger.
- [REFERENCING OLD AS o NEW AS n] – Essa parte permite que você consulte os valores novos e antigos para várias instruções DML, como INSERT, UPDATE e DELETE.
- [FOR EACH ROW] – Adiciona um trigger para cada linha afetada. Caso não seja especificado, a Trigger só será chamada apenas uma vez, isso tem o nome de table level Trigger.
- WHEN (condição) – Fornece uma condição para as linhas nas quais a Trigger seria disparada. Essa cláusula é válida apenas para Triggers em nível de linha.
Exemplo:
No código em seguida temos uma tabela com clientes e sempre que houver uma mudança nessa tabela, acionaremos a nossa Trigger. Criamos um gatilho em nível de linha para a nossa tabela e as ações que iremos observar são INSERT, UPDATE e DELETE. Essa Trigger exibirá a diferença de salários entre os valores antigos e os novos:
Select * from clientes;
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
+----+----------+-----+-----------+----------+
CREATE OR REPLACE TRIGGER mostrar_diferenca_salario
BEFORE DELETE OR INSERT OR UPDATE ON clientes
FOR EACH ROW
WHEN (NEW.ID > 0)
DECLARE
sal_diff number;
BEGIN
sal_diff := :NEW.salary - :OLD.salary;
dbms_output.put_line('Salário antigo: ' || :OLD.salary);
dbms_output.put_line('Novo salário: ' || :NEW.salary);
dbms_output.put_line('Diferença dos salários: ' || sal_diff);
END;
/ Quando você executar esse código, provavelmente terá uma mensagem de sucesso.
Executando uma Trigger
Vamos começar a fazer algumas operações DML na tabela de clientes. Iniciamos com uma instrução INSERT, que criará uma nova linha. Logo em seguida já teremos a chamada da nossa Trigger:
INSERT INTO CLIENTES (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (7, 'João', 22, 'HP', 7500.00 ); Salário antigo:
Novo salário: 7500
Diferença dos salários:Já que esse é o primeiro registro da tabela com esse id, o salário anterior não está disponível e o resultado acima é nulo. Vamos executar novamente uma operação DML na tabela dos clientes, só que dessa vez utilizando o UPDATE para atualizar um registro:
UPDATE clientes
SET salary = salary + 500
WHERE id = 2;
-- Resposta:
Salário antigo: 1500
Novo salário: 2000
Diferença dos salários: 500JOBs
O Job nada mais é do que uma tarefa que é executada pelo Oracle a partir de um texto por tempo.
O código do Job é assim:
BEGIN
BEGIN
SYS.DBMS_SCHEDULER.DROP_JOB('job_trybe');
EXCEPTION WHEN OTHERS THEN NULL;
END;
dbms_scheduler.create_job(
job_name => 'JOB_TRYBE',
job_type => 'PLSQL_BLOCK',
job_action => 'CRIARPOST',
ENABLED => TRUE,
AUTO_DROP => TRUE,
START_DATE => SYSDATE,
REPEAT_INTERVAL => 'FREQ=SECONDLY; BYSECOND=0,10,20,30,40,50');
END;Nesse código criamos um Job que chamará uma ação a cada repetição do intervalo.
Views
Conseguimos definir uma View como uma consulta predefinida inspirada em uma ou mais tabelas. As Views podem receber consultas exatamente como uma tabela, para tanto precisa-se passar o nome da(s) view(s) na cláusula FROM dentro da consulta SQL.
As Views proporcionam algumas vantagens e são divididas em 2 tipos:
- Views simples — Aqui recuperamos as linhas de uma única tabela base, não contém nenhuma função de grupo e consegue aceitar as operações DML.
- Views complexas — Nesse caso podemos recuperar linhas de várias tabelas, temos funções de grupo e em algumas ocasiões não podemos realizar operações DML.
Sintaxe de uma View:
CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW nome_da_view
[(alias[, alias]...)]
AS subquery
[WITH CHECK OPTION [CONSTRAINT nome_Constraint]]
[WITH READ ONLY [CONSTRAINT nome_Constraint]];Sintaxe de uma View simples:
CREATE VIEW V_itens
AS
SELECT id, nome, quantidade
FROM
t_itens;Sintaxe de uma View complexa:
CREATE VIEW V_itens
AS
SELECT id, nome, quantidade, estoque
FROM
t_itens I,
tdepartamento D
WHERE
D.departamento_id = I.item_id;Ambiente de execução do PLSQL
PL/SQL não é uma linguagem de programação standalone e sim uma ferramenta dentro de um ambiente de programação Oracle. Para executar o ambiente do PL/SQL, podemos utilizar o SQL* Plus que basicamente nos permite digitar as instruções PL/SQL no prompt de comando. Todos os comandos são enviados para o banco de dados para o processamento. Depois que as declarações são processadas, os resultados são enviados de volta e exibidos na tela.
Para executar programas PL/SQL, você precisará ter o Oracle RDBMS Server instalado na sua máquina. Entre no site oficial da Oracle para baixar esse arquivo. No momento que esse texto está sendo produzido, a versão mais recente é a 19c!
Desenvolvedor PL/SQL: o que faz, salário e carreira!
O seu principal trabalho como desenvolvedor ou desenvolvedora PL/SQL será escrever consultas baseadas em SQL para melhorar o desempenho das instruções do banco de dados. Também será exigido que você analise os resultados de operações e forneça soluções, sugestões a clientes finais e também relacionadas à criação de documentos.
As principais características de um desenvolvedor PL/SQL são:
- Conhecimento profundo de banco de dados Oracle.
- Boa compreensão de construções de programas, procedures, Packages, Triggers e escrita de instruções.
- Conhecimento sólido na área de desenvolvimento de software e deve ser capaz de seguir processos padrões, como revisão de código, criação e execução de casos de testes unitários.
- Ser capaz de criar modelos de dados, design e implementação
- Ser capaz de ajustar o desempenho das consultas SQL.
No Brasil, a média salarial de um desenvolvedor PL/SQL é de R$5.230, de acordo com o site Glassdoor.
PL/SQL é uma linguagem de programação procedural que é estendida pela linguagem de programação do banco de dados da Oracle. Como já mostramos ao decorrer do texto, PL/SQL consegue aproveitar o melhor dos dois mundos, podendo realizar operações no banco de dados e ao mesmo tempo criar estruturas de dados que auxiliam na criação de programas e aplicativos.
Além de tudo isso, é uma ferramenta que tem um alto posicionamento no mercado, já que é da família Oracle. Com o PL/SQL, temos diversas possibilidades e o céu é realmente o limite. Podemos criar aplicativos na web, programas nativos e muito mais, tudo apenas utilizando essa linguagem.
Tem interesse em aprender mais sobre banco de dados? Então leia um pouco mais sobre MongoDB: o que é e como usar o banco de dados NoSQL?


