
O aprendizado supervisionado é uma subcategoria de machine learning e da inteligência artificial.
De forma simples, é um tipo de aprendizado em que uma máquina é treinada usando dados “rotulados”, ou seja, que foram identificados com rótulos que identificam alguma característica.
Isso é muito importante porque os algoritmos podem usar dados rotulados como alimento para a tomada de decisão.
Mas a importância do aprendizado supervisionado vai além.
Deseja saber mais? Fique com a gente que vamos fazer comparações com outros tipos de aprendizagem.
- O que é o aprendizado supervisionado e como funciona?
- Quais os principais tipos de aprendizado supervisionado? 7 exemplos na prática!
- Aprendizado supervisionado, não supervisionado, semi supervisionado e por reforço? Qual é o melhor?
- O passo a passo para usar o aprendizado de máquina supervisionado!
O que é o aprendizado supervisionado e como funciona?
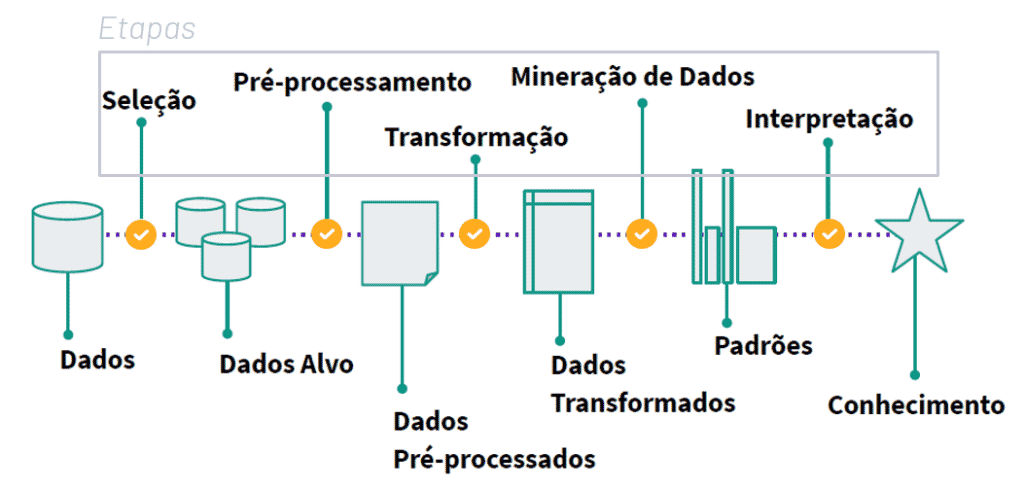
O aprendizado supervisionado, também conhecido como aprendizado de máquina supervisionado, é uma subcategoria de machine learning e inteligência artificial. É definido pelo uso de conjuntos de dados rotulados para treinar algoritmos que classificam dados ou predizem resultados com precisão.
À medida que os dados de entrada são inseridos no modelo, ele ajusta seus pesos até que o modelo seja ajustado adequadamente — o que ocorre como parte do processo de validação cruzada. O aprendizado supervisionado ajuda as organizações a resolver uma variedade de problemas do mundo real em escala.
Quer um exemplo?
No e-mail que usamos temos a classificação de spam em uma pasta separada de sua caixa de entrada, permitindo com que emails importantes não se confundam com emails ruins. Entende?
O aprendizado supervisionado usa um conjunto de treinamento para ensinar os modelos a produzir a saída desejada. Esse conjunto de dados de treinamento inclui entradas e saídas corretas, que permitem que o modelo aprenda ao longo do tempo.
O algoritmo mede sua precisão através da função de perda, ajustando até que o erro tenha sido suficientemente minimizado.
O que é o machine learning?
O machine learning (aprendizado de máquina) é um subcampo da inteligência artificial (IA). O objetivo do aprendizado de máquina geralmente é entender a estrutura dos dados e encaixá-los em modelos que possam ser compreendidos e utilizados pelas pessoas.
Embora o aprendizado de máquina seja um campo da ciência da computação, ele difere das abordagens computacionais tradicionais. Na computação tradicional, algoritmos são conjuntos de instruções explicitamente programadas usadas por computadores para calcular ou resolver problemas.
Os algoritmos de aprendizado de máquina permitem que os computadores treinem nas entradas de dados e usem a análise estatística para gerar valores de saída que se enquadram em um intervalo específico. Por causa disso, o aprendizado de máquina facilita a construção de modelos pelos computadores a partir de dados de amostra, automatizando os processos de tomada de decisão com base nas entradas de dados.
Quais os principais tipos de aprendizado supervisionado? 7 exemplos na prática!
Banco de dados para exemplos
Antes de nos aprofundarmos nas principais categorias de aprendizado supervisionado, precisamos de um contexto para os nossos exemplos. Neste caso, utilizaremos a ideia de que um marketplace quer usar o aprendizado de máquina para entender os gostos de clientes, qual a periodicidade de suas compras, quais são seus produtos preferidos, etc.
Em um banco de dados, temos os seguintes dados de uma pessoa usuária:
- ID: identificador da pessoa cliente;
- Idade: idade da pessoa cliente;
- Gênero: gênero da pessoa cliente (nesse caso utilizaremos o gênero binário, masculino ou feminino);
- Data: data em que a pessoa cliente efetuou a compra;
- Produto Id: identificador do produto comprado;
- Avaliação do produto: avaliação do produto por outras pessoas clientes;
- Avaliação do produto cliente: nota de 1 a 5 que a pessoa cliente deu para o produto;
- Valor total: valor gasto na compra.
Apenas lembrando que os campos de avaliação são opcionais, levando em conta que nem toda pessoa usuária avalia a sua compra. Agora que temos os dados, conseguimos continuar a nossa jornada pelos algoritmos de aprendizado de máquina supervisionado.
Classificação
A classificação é um conceito de aprendizado supervisionado que basicamente categoriza um conjunto de dados em classes, como Sim ou Não, 0 ou 1, Spam ou Não Spam, gato ou cachorro, etc. As classes podem ser chamadas de rótulos ou categorias.
Classificação binária
É um processo ou tarefa de classificação em que um dado está sendo classificado em duas classes. É um tipo de previsão que define a qual dos dois grupos determinada coisa pertence.
Exemplo de uso
Com os dados de última compra de algumas pessoas usuárias:
| ID | Idade | Gênero | Avaliação do produto cliente | Produto Id |
| 1 | 35 | H | Sem avaliação | 1564 |
| 2 | 26 | M | 2 | 1425 |
| 3 | 68 | H | 5 | 293 |
| 4 | 20 | M | 3 | 1350 |
| 5 | 53 | M | Sem avaliação | 3042 |
Conseguimos determinar quais comprariam um perfume novo, por exemplo:
| Perfume |
| 0 |
| 1 |
| 1 |
| 1 |
| 0 |
Pronto. Tendo as informações de entrada, o nosso algoritmo define, a partir das compras das pessoas usuárias, se elas comprariam (1) ou não (0) um produto. Assim, definimos a quem exibir esse perfume na tela inicial do aplicativo.
Esse modelo de negócio é curioso, pois torna única a experiência de cada pessoa e, consequentemente, aumenta o número de vendas.
Quais as aplicações na vida real
A classificação binária é amplamente utilizada para os seguintes itens:
- Detecção de spam de e-mail (spam ou não);
- Previsão de churn (churn ou não);
- Previsão de conversão (comprar ou não).
Classificação multiclasse
Ao contrário da classificação binária, a classificação multiclasse não tem a noção de resultados normais e anormais. Em vez disso, os exemplos são classificados como pertencentes a uma dentre várias classes conhecidas.
Exemplo de uso
Temos novamente uma entrada de dados de algumas pessoas usuárias:
| ID | Idade | Gênero | Avaliação do produto cliente | Produto Id |
| 6 | 53 | M | 4 | 2049 |
| 7 | 62 | H | 3 | 154 |
| 8 | 28 | H | 1 | 9093 |
| 9 | 39 | M | Sem avaliação | 4002 |
| 10 | 40 | H | Sem avaliação | 503 |
Com essas informações, conseguimos oferecer opções de um produto de diversas marcas, como um perfume, novamente:
| Perfume |
| A ou B ou C |
| B ou C ou D |
| A ou B ou D |
| A ou C ou D |
| A ou B ou C |
O algoritmo de aprendizado supervisionado classifica quais são as melhores marcas para cada perfil de pessoa usuária. Dessa maneira, criamos ainda mais filtros para quem vai consumir e tornamos a experiência como um todo muito mais agradável.
Quais as aplicações na vida real
A classificação multiclasse é usada principalmente em:
- Classificação de rostos;
- Classificação das espécies vegetais;
- Reconhecimento óptico de caracteres.
Classificação multirrótulo
A classificação multirrótulo nos permite classificar conjuntos de dados com mais de uma variável de destino. Na classificação multirrótulo, os vários rótulos são as saídas para uma determinada previsão. Ao fazer previsões, uma determinada entrada pode pertencer a mais de um rótulo.
Exemplo de uso
Temos a seguinte entrada de dados:
| ID | Idade | Gênero | Avaliação do produto cliente | Produto Id |
| 11 | 29 | H | 5 | 905 |
| 12 | 46 | M | 2 | 4055 |
| 13 | 70 | M | 5 | 3054 |
| 14 | 19 | M | 1 | 2031 |
| 15 | 30 | H | 1 | 5320 |
E o resultado:
| Blusa |
| Cor A, Tamanho A, Tecido A |
| Cor B, Tamanho C, Tecido A |
| Cor A, Tamanho C, Tecido C |
| Cor B, Tamanho B, Tecido B |
| Cor B, Tamanho A, Tecido A |
Neste outro exemplo, o algoritmo consegue determinar qual a melhor cor, tamanho e tecido de blusa para cada pessoa usuária. Essa classificação é muito importante para destacar os principais produtos e aumentar o foco naqueles que cada perfil de pessoa usuária tem mais probabilidade de se interessar.
Quais as aplicações na vida real
A classificação multirrótulo é usada principalmente em algoritmos mais complexos, como:
- Decision Trees;
- Random Forests;
- Gradient Boosting.
Classificação desequilibrada
A classificação desequilibrada refere-se a um problema de modelagem preditiva de classificação em que o número de exemplos no conjunto de dados de treinamento para cada rótulo de classe não é balanceado. Ou seja, onde a distribuição de classes não é igual ou próxima de igual e, em vez disso, é tendenciosa ou enviesada.
Exemplo de uso
Na entrada temos:
| ID | Idade | Gênero | Avaliação do produto cliente | Produto Id |
| 16 | 40 | M | Sem avaliação | 2942 |
| 17 | 24 | M | 4 | 231 |
| 18 | 32 | H | 3 | 9321 |
| 19 | 58 | H | Sem avaliação | 7583 |
| 20 | 68 | M | 2 | 2342 |
E a saída fica:
| Produto |
| 1 |
| 1 |
| 1 |
| 1 |
| 1 |
Se você reparar, temos um problema em nosso resultado: todos deram positivos (1), ou seja, temos uma classificação desequilibrada. Em casos como esse, devemos rever os dados que estamos utilizando ou até mesmo o algoritmo.
Quais as aplicações na vida real
A classificação desequilibrada é mais usada em:
- Detecção de fraude;
- Detecção de outliers;
- Testes de diagnóstico médico.
Regressão
A análise de regressão é um método estatístico para modelar a relação entre uma variável dependente (alvo) e independente (preditor) com uma ou mais variáveis independentes. Mais especificamente, a análise de regressão nos ajuda a entender como o valor da variável dependente está mudando correspondente a uma variável independente quando outras variáveis independentes são mantidas fixas. Ele é utilizado em junção com valores contínuos/reais, como temperatura, idade, salário, preço, etc.
Regressão linear
A regressão linear é um dos algoritmos de aprendizado supervisionado mais fáceis e populares. É um método estatístico que é usado para análise preditiva. A regressão linear faz previsões para variáveis contínuas/reais ou numéricas, como vendas, salário, idade, preço do produto, etc.
Exemplo de uso
Valores de entrada:
| ID | Idade | Gênero | Valor total | Data |
| 1 | 35 | H | R$ 74,10 | 07/07/2021 |
| 2 | 26 | M | R$ 150,90 | 03/07/2021 |
| 3 | 68 | H | R$ 300,45 | 04/07/2021 |
| 4 | 20 | M | R$ 50,79 | 01/07/2021 |
| 5 | 53 | M | R$ 400,00 | 09/07/2021 |
E o resultado ficou:
| Valor de compra |
| R$ 160,90 |
| R$ 200,30 |
| R$ 350,10 |
| R$ 100,39 |
| R$ 410,00 |
O nosso modelo mostra qual o possível valor que determinada pessoa usuária gastaria em nossa loja. Caso o valor seja muito superior ao real, significa que não estamos destacando os produtos corretamente para esta pessoa. A lógica principal do algoritmo é predizer o valor “real” de compra.
Quais as aplicações na vida real
A principal aplicação da regressão linear é a previsão de valores, ou seja, tentar prever quanto de retorno uma ação de marketing em uma empresa consegue dar.
Regressão logística
A regressão logística é um algoritmo de classificação de aprendizado supervisionado usado para prever a probabilidade de uma variável. A variável em si, deve possuir apenas duas classes possíveis, ou seja, valor 1 (significa sucesso/sim) ou 0 (significa falha/não).
Exemplo de uso
Valores de entrada:
| ID | Idade | Gênero | Valor total | Data |
| 6 | 46 | H | R$ 74,10 | 07/07/2021 |
| 7 | 30 | H | R$ 150,90 | 03/07/2021 |
| 8 | 23 | M | R$ 300,45 | 04/07/2021 |
| 9 | 60 | H | R$ 50,79 | 01/07/2021 |
| 10 | 53 | M | R$ 400,00 | 09/07/2021 |
E o resultado ficou:
| Voltariam a comprar |
| 1 |
| 0 |
| 1 |
| 1 |
| 0 |
Nesse exemplo, temos a previsão de recompra das pessoas usuárias a partir de algumas informações. Nesse caso, o resultado é um valor binário, onde 1 é positivo para a compra e 0, o contrário. A regressão logística é bem semelhante com a ideia da classificação binária.
Quais as aplicações na vida real
A regressão logística é usada principalmente em:
- Prever a probabilidade de uma pessoa ter um ataque cardíaco;
- Prever a propensão de uma pessoa cliente a comprar um produto ou interromper uma assinatura;
- Prever a probabilidade de falha de um determinado processo ou produto.
Regressão polinomial
A regressão polinomial é um caso especial de regressão linear onde ajustamos uma equação polinomial nos dados com uma relação curvilínea entre a variável independente x e a variável dependente y, e modelamos como um polinômio de grau n.
Exemplo de uso
Valores de entrada:
| ID | Idade | Gênero | Valor total | Data |
| 11 | 46 | H | R$ 74,10 | 07/07/2021 |
| 12 | 30 | H | R$ 150,90 | 03/07/2021 |
| 13 | 23 | M | R$ 300,45 | 04/07/2021 |
| 14 | 60 | H | R$ 50,79 | 01/07/2021 |
| 15 | 53 | M | R$ 400,00 | 09/07/2021 |
E o resultado ficou:
| Valor de futura compra |
| R$ 130,20 |
| R$ 200,45 |
| R$ 340,00 |
| R$ 75,60 |
| R$ 608,50 |
Aqui temos uma previsão de valores nas próximas compras de cada pessoa usuária. O algoritmo define um polinômio com base nos dados de entrada e, assim, conseguimos entender a progressão dos valores de compra.
Quais as aplicações na vida real
A regressão polinomial é usada principalmente em:
- Modelo de previsão de casos Covid-19;
- Preditor de salário de cargos (júnior, pleno, sênior, etc).
Aprendizado supervisionado, não supervisionado, semi supervisionado e por reforço? Qual é o melhor?
Supervisionado
No modelo de aprendizado supervisionado, os grupos de dados são rotulados e usados para prever algum tipo de evento futuro, basicamente. Para isso, é criado uma fórmula de treinamento onde temos que a entrada é um conjunto de dados que corresponde a vários rótulos, logo depois, um algoritmo de aprendizado cria a função inferida para realizar observações nas previsões que a gente modelou.
Dessa forma, com o modelo devidamente treinado e estabelecido, o algoritmo que aprende compara também as saídas com os retornos desejados. A partir dos erros que ele encontra, são feitas modificações e melhorias.
Não supervisionado
Com a premissa de dados não rotulados e uma estrutura oculta, o aprendizado não supervisionado tem seus sistemas baseados em encontrar uma conclusão que descreva estas estruturas ocultas e dados não rotulados, e na não prevenção de uma saída correta. Basicamente, é um modelo bem aleatório, mas que com o devido treinamento e dados, podem encontrar vários tipos de resultados.
Semi supervisionado
Aqui temos uma junção dos dois modelos supervisionados e não supervisionados, onde são usados tanto os dados rotulados, como os não rotulados.
Por reforço
Essa parte de modelos por reforço consiste em algoritmos que utilizam os erros estimados como recompensas ou penalidades. Se o erro for grande, então a penalidade é alta e a recompensa baixa. Se o erro for pequeno, então a penalidade é baixa e a recompensa é alta.
Usando modelos de aprendizado de máquina (ML), somos capazes de realizar análises de grandes quantidades de dados. Padrões de dados que seriam impossíveis de identificar por um ser humano podem ser extraídos com precisão usando esses modelos de ML em segundos (em alguns casos). No entanto, na maioria das vezes, resultados precisos (bons modelos) geralmente exigem muito tempo e recursos para o treinamento do modelo (o procedimento sob o qual o modelo aprende uma função ou um limite de decisão).
O passo a passo para usar o aprendizado de máquina supervisionado!
Preparando os dados
Todos os métodos de aprendizado supervisionado começam com uma matriz de dados de entrada, geralmente chamada de X aqui. Cada linha de X representa uma observação. Cada coluna de X representa uma variável ou preditor. Representamos as entradas ausentes com valores NaN em X.
Escolhendo um algoritmo
Existem várias características entre os algoritmos, como:
- Velocidade de treinamento;
- Uso de memória;
- Precisão preditiva em novos dados;
- Transparência ou interpretabilidade (ou seja, com que facilidade você pode entender os motivos pelos quais um algoritmo faz suas previsões).
Escolhendo um modelo
Além dos modelos de aprendizado supervisionado que vimos no artigo, também temos:
- Análise Discriminante (classificação);
- k-Vizinhos mais próximos (classificação);
- Naive Bayes (classificação);
- Máquinas de vetor de suporte (em inglês Support Vector Machines, SVM) para classificação;
- SVM para regressão;
- Modelos multiclasse para SVM ou outros classificadores;
- Conjuntos de Classificação;
- Conjuntos de regressão.
Escolha um método de validação
Os três principais métodos para examinar a precisão do modelo ajustado resultante são:
- Examinador de erro de substituição;
- Examinador de erro de validação cruzada;
- Examinador de erro para árvores de decisão empacotadas.
Verificar o modelo e ajustá-lo até o uso correto
Por fim, depois de validar o modelo, talvez você queira alterá-lo para obter melhor precisão, velocidade ou usar menos memória. Ou seja, avalie a previsão do seu modelo e tente sempre melhorá-lo.
Conclusão
O aprendizado supervisionado é o primeiro passo para o aprendizado de máquina e serve como uma introdução para muitos praticantes de aprendizado de máquina. Além disso é a forma mais usada de aprendizado de máquina e tem provado ser uma excelente ferramenta para muitos campos.
Um exemplo de uso do aprendizado supervisionado são as recomendações que aparecem na primeira tela de alguns aplicativos. Muito provavelmente, elas utilizam o aprendizado de máquina para entender quais opções exibir de acordo com cada perfil de pessoa cliente.
Na categorização do aprendizado de máquina, temos o supervisionado e o não supervisionado. Dentre os dois, fica a critério de como os dados estão portados para o treinamento. Caso você precise rotular um subconjunto de dados, a melhor opção é o supervisionado. No caso dos não supervisionados, o grande volume de dados é mais propenso.
Além disso, vemos que existe uma grande preparação para a execução dos algoritmos de inteligência artificial, precisamos preparar os dados, escolher com calma os métodos e modelos que serão utilizados e verificar se os resultados estão concisos.
Agora, que tal aprofundar o seu conhecimento sobre inteligência artificial com o nosso artigo Python: o que é, como usar, guia pra aprender a linguagem? Vamos lá!


