
“Scraping”, embora para muitas pessoas soe como um conceito totalmente novo, sua história pode ser datada da época em que a World Wide Web nasceu.
Antes do desenvolvimento dos mecanismos de pesquisa, a Internet era apenas uma coleção de sites de protocolo de transferência de arquivos (FTP) nos quais as pessoas navegavam para encontrar arquivos compartilhados específicos.
As pessoas começaram a achar simples buscar as informações que desejam, mas o problema ocorria quando eles queriam obter dados da Internet — nem todos o site oferecia opções de download, e copiar manualmente era tedioso e ineficiente.
E é aí que entrou o web scraping. O web scraping é, na verdade, movido por web bots/crawlers que funcionam da mesma forma que aqueles usados nos motores de busca. Ou seja, buscar e copiar.
Quer saber mais sobre o que é Scraping e como funciona? Veja o conteúdo que preparamos a seguir:
- O que é o scraping?
- Como funciona o scraping?
- Para que o web scraping é usado?
- Quais os 4 tipos de web scrapers?
- Quais os benefícios do web scraping?
- Quais as diferenças entre web crawling e web scraping?
- Principais cuidados para tomar antes de aplicar o scraping!
- Como fazer um web scraping? O passo a passo!
- Por que Python é usada para fazer web scraping?
- Como fazer um web scraping Python? Tutorial!
- Qual a relação entre web scraping e big data?
- Quais os riscos do scraping para quem tem os dados coletados?
- Como se proteger dos riscos do scraping?
- Web scraping é crime?
- Quanto custa um web scraping?
O que é o scraping?
Web scraping é uma técnica para extrair grandes quantidades de dados de sites. Mas por que é necessário obter uma quantidade tão grande de dados de sites? Veja os seguintes aplicativos de web scraping para saber mais:
- Comparação de preços e monitoramento da concorrência: as ferramentas de web scraping podem monitorar os dados dos produtos de catering desta empresa a qualquer momento.
- Treinar e testar dados para projetos de aprendizado de máquina: Web scraping auxilia na coleta de dados para o teste e treinamento de modelos de aprendizado de máquina.
- Pesquisa acadêmica.
- Reunir avaliações e classificações de hotéis / restaurantes de sites como o TripAdvisor.
- Usar sites como Booking.com e Hotels.com para verificar preços e informações de quartos de hotel.
- Raspar tweets do Twitter associados a uma conta ou hashtag específica.
- Extrair informações de contato comercial, como números de telefone e endereços de e-mail de sites de páginas amarelas ou listas de empresas do Google Maps para gerar leads para marketing.
Como funciona o scraping?
Geralmente, web scraping envolve três etapas:
- Primeiro, enviamos uma solicitação GET ao servidor e receberemos uma resposta na forma de conteúdo da web.
- A seguir, analisamos o código HTML de um site da Web seguindo um caminho de estrutura de árvore.
- Por fim, usamos a biblioteca python para pesquisar a árvore de análise.
A raspagem da web parece boa no papel, mas na verdade é mais complexa na prática. Precisamos de codificação para obter os dados que queremos, o que torna o privilégio de quem é mestre da programação.
Porém, como alternativa, existem ferramentas de web scraping que automatizam a extração de dados da web.
Uma ferramenta de web scraping carregará os URLs fornecidos pelas pessoas usuárias e vai renderizar todo o site. Como resultado, você pode extrair quaisquer dados da web com um simples apontar e clicar, arquivando em um formato viável para o seu computador sem codificação.
Para que o web scraping é usado?
Existem inúmeras aplicações de web scraping, que podem ser subdivididas em diferentes categorias, veja a seguir:
Monitoramento de preços do concorrente
Nesta era de comércio eletrônico, o preço desempenha um papel fundamental. Você precisa acompanhar as estratégias de preços da concorrência.
No entanto, tentar controlar os preços manualmente não é uma opção viável. Além disso, os preços continuam mudando de vez em quando. Portanto, torna-se praticamente impossível acompanhar os preços de forma manual.
É aqui que entra o web scraping. Ele automatiza o processo de extração de preços de concorrentes e mantém você atualizado sobre as novas estratégias de preços implementadas.
Monitorando a opinião do consumidor
É necessário rastrear e analisar o sentimento da pessoa consumidora. Isso é feito analisando-se o feedback do consumidor e as avaliações de diferentes empresas.
No entanto, obter todos os comentários de diferentes sites de forma manual não é viável.
Portanto, a web scraping é aproveitada para torná-la incrivelmente fácil. Com o web scraping, você pode obter todos os comentários em uma planilha e até comparar diferentes comentários com base em palavras-chave.
Aplicativos de Web Scraping em pesquisas financeiras e patrimoniais
Artigos de notícias agregados
No campo das finanças e seguros, as notícias são a grande fonte de insights. No entanto, não é possível ler todos os jornais e todos os artigos manualmente. Portanto, web scraping é usado para extrair informações valiosas de diferentes notícias, manchetes, etc., para convertê-las em insights de investimento acionáveis.
Agregação de dados de mercado
Embora muitos dados de mercado estejam disponíveis na Internet, eles estão espalhados por dezenas de milhares de sites.
Você pode pesquisar e verificar os resultados da pesquisa, mas é muito demorado e tedioso.
O web scraping é usado para extrair os dados de diferentes sites e obter inteligência acionável em termos de pesquisa de ações.
Aplicativos de Web Scraping em Produto, Marketing e Vendas
Marketing baseado em dados
Os dados são essenciais para qualquer empreendimento de marketing e vendas. Não há nada de novo nisso. No entanto, o acesso aos dados é algo que às vezes distingue dois profissionais de marketing. O web scraping pode disponibilizar os dados para formular as estratégias.
Marketing de conteúdo
Quando se trata de marketing de conteúdo, web scraping é usado para coletar dados de diferentes sites, como Twitter, Tech Crunch etc. Esses dados, então, podem ser usados para criar conteúdo envolvente.
Geração de Leads
No que diz respeito à geração de leads , muitas empresas têm que gastar muito dinheiro para obter leads de saída. Isso pode queimar seu orçamento. Em vez disso, a web scraping é aproveitada para extrair dados diretamente de diferentes fontes e gerar leads.
Desta forma, leads de qualidade podem ser gerados a um custo baixo e o orçamento pode ser usado em outras coisas importantes.
Monitoramento de SEO
Bem, os mecanismos de pesquisa nos dizem muito sobre como o mundo dos negócios se move. A forma como o conteúdo sobe e desce nas classificações também é uma chave para o sucesso na era da Internet.
Pode-se estudar a maneira como o conteúdo funciona na Internet e derivar ideias e estratégias.
No entanto, isso não pode ser feito manualmente. Portanto, há um uso crescente de ferramentas de web scraping para extrair os dados sobre o que acontece nos bastidores dos mecanismos de pesquisa.
Monitoramento de reputação
É vital entender como clientes se sentem em relação a você e sua marca. Você pode ter uma ideia vaga sobre isso, mas fornecer uma conta com base em dados pode ser difícil.
No entanto, as ferramentas de web scraping tornaram-se tão sofisticadas que agora são capazes de extrair comentários de clientes e outras informações de sites e facilitar o monitoramento de marca ou reputação com bastante facilidade.
Motor de busca para sites classificados
Existem sites que funcionam como motor de busca de anúncios classificados.
No entanto, não é possível buscar esses dados manualmente. As ferramentas de web scraping são utilizadas para rastrear e extrair as especificações técnicas.
Os dados são usados no site para os visitantes pesquisarem e acessarem.
Quais os 4 tipos de web scrapers?

Para simplificar, dividiremos alguns desses aspectos em 4 categorias . Evidentemente, existem mais complexidades em jogo ao comparar web scrapers.
- auto-construído ou pré-construído
- extensão do navegador ou software
- Interface de usuário
- Nuvem ou Local
Auto-construído ou pré-construído
Assim como qualquer pessoa pode construir um site, qualquer pessoa pode construir seu próprio raspador de web.
No entanto, as ferramentas disponíveis para construir seu próprio web scraper ainda requerem algum conhecimento avançado de programação. O escopo desse conhecimento também aumenta com o número de recursos que você gostaria que seu raspador tivesse.
Por outro lado, existem vários web scrapers pré-construídos que você pode baixar e executar imediatamente. Alguns deles também terão opções avançadas adicionadas, como agendamento de scrap, exportação de JSON, Planilhas Google e muito mais.
Extensão do navegador ou software
Em termos gerais, os web scrapers vêm em duas formas: extensões do navegador ou software de computador.
Extensões de navegador são programas semelhantes a aplicativos que podem ser adicionados a seus navegadores, como Google Chrome ou Firefox.
As extensões de web scraping têm a vantagem de serem mais simples de executar e integradas diretamente ao seu navegador.
No entanto, essas extensões geralmente são limitadas. O que significa que quaisquer recursos avançados que precisassem ocorrer fora do navegador seriam impossíveis de implementar. Por exemplo, Rotações de IP não seriam possíveis neste tipo de extensão.
Por outro lado, você poderá ter um software real de web scraping que pode ser baixado e instalado em seu computador. Embora sejam um pouco menos convenientes do que as extensões do navegador, eles compensam em recursos avançados que não são limitados pelo que o seu navegador pode ou não pode fazer.
Interface de usuário
A interface do usuário entre os web scrapers pode variar bastante.
Por exemplo, algumas ferramentas de web scraping serão executadas com uma IU mínima e uma linha de comando. Algumas pessoas usuárias podem achar isso pouco intuitivo ou confuso.
Por outro lado, alguns web scrapers terão uma IU completa, onde o site é totalmente renderizado para que a pessoa usuária apenas clique nos dados que deseja copiar. Esses web scrapers são geralmente mais fáceis de trabalhar para a maioria das pessoas com conhecimento técnico limitado.
Alguns scrapers chegam ao ponto de integrar dicas e sugestões de ajuda por meio de sua IU para garantir que a pessoa entenda cada recurso que o software oferece.
Nuvem ou Local
De onde seu raspador da web realmente faz seu trabalho?
Os web scrapers locais serão executados em seu computador usando seus recursos e conexão com a Internet. Isso significa que se o raspador da web usa muito CPU ou RAM, o computador pode ficar muito lento enquanto o raspador é executado. Com longas tarefas de raspagem, isso poderia deixar o computador fora de serviço por horas.
Além disso, se o seu raspador estiver configurado para ser executado em um grande número de URLs (como páginas de produtos), isso pode ter um impacto nos limites de dados do seu ISP.
Raspadores da web baseados em nuvem são executados em um servidor externo que geralmente é fornecido pela empresa que desenvolveu o próprio raspador. Isso significa que os recursos do seu computador são liberados enquanto o raspador é executado e coleta dados.
Isso também permite uma integração muito fácil de recursos avançados, como rotação de IP, que pode evitar que seu scraper seja bloqueado nos principais sites devido à atividade de scraping.
Quais os benefícios do web scraping?
1. Custo-benefício
Os serviços de web scraping fornecem um serviço essencial a um custo competitivo. Os dados terão que ser coletados de sites e analisados para que a internet funcione regularmente. Os serviços de web scraping conseguem fazer isso de maneira econômica.
2. Baixa manutenção e velocidade
O Web Scraping tem um custo de manutenção muito baixo associado a ele por um certo tempo. Dessa forma, ajuda a planejar o orçamento com precisão. Além disso, copiar a web economiza muito tempo, pois pode fazer o trabalho manual de um dia em poucas horas.
3. Precisão de dados
Erros simples na extração de dados podem levar a grandes problemas. Portanto, é necessário garantir que os dados sejam corretos . A extração de dados não é apenas um processo rápido, mas também precisa. Essa reputação ajuda na coleta de dados importantes, como preço de venda, dados financeiros, para citar alguns.
4. Fácil de implementar
Assim que um serviço de scraping de site começa a coletar dados, você pode ter certeza de que está obtendo dados não apenas de uma única página, mas de todo o domínio. Com um investimento único, pode ter um grande volume de dados.
Quais as diferenças entre web crawling e web scraping?
O rastreamento da Web(crawling), também conhecido como Indexação, é usado para indexar as informações na página usando bots também conhecidos como rastreadores. O rastreamento é essencialmente o que os motores de busca fazem. É uma questão de visualizar uma página como um todo e indexá-la. Quando um bot rastreia um site, ele passa por todas as páginas e todos os links, até a última linha do site, em busca de qualquer informação.
Os rastreadores da Web são usados basicamente pelos principais mecanismos de pesquisa como Google, Bing, Yahoo, agências de estatísticas e grandes agregadores online. O processo de rastreamento da web geralmente captura informações genéricas, enquanto o web scraping se concentra em fragmentos de conjuntos de dados específicos.
Web scraping é uma forma automatizada de extrair conjuntos de dados específicos usando bots que também são conhecidos como ‘scrapers’. Depois que as informações desejadas são coletadas, elas podem ser usadas para comparação, verificação e análise com base nas necessidades e objetivos de um determinado negócio.
Principais cuidados para tomar antes de aplicar o scraping!
Etapa 1: pense como uma máquina, não como um humano
Basicamente, um site é uma mistura de código HTML. Os sites estáticos ou dinâmicos contêm seu código HTML em todas as páginas da web dos sites. Por esse motivo, use uma ferramenta de raspagem para extrair os dados da página da web . O script definirá a máquina. Sempre que for necessário extrair o código do site, você pode fazer isso facilmente clicando em um único botão em sua ferramenta de remoção.
Mas isso não funcionará sempre que você fizer um scraping, porque sites dinâmicos podem ser alterados a qualquer momento e sua ferramenta de scraping não consegue entender quais alterações ocorreram no site. Mas um cérebro humano pode reconhecer no site onde e quais mudanças ocorreram.
Portanto, você precisará reescrever seu código HTML ou editá-lo no script de uma página da web. Pode levar algumas horas para fazer alterações. Para resolver esse problema, as pessoas desenvolvedoras foram ensinadas a usar ferramentas de raspagem para perceber como o cérebro humano ou o entendimento humano o fazem.
Esses passos incríveis foram dados por desenvolvedores chamados de “Abstração de Visualização”. Essa abstração visual aplica o código de aprendizado de máquina para aprimorar a máquina para extrair os dados da página da web como as pessoas fazem.
Etapa 2: configurar sua ferramenta de raspagem
Você pode raspar um site com a ajuda de qualquer linguagem de programação. Porém, é recomendado usar Python durante o web scraping. Por que Python? Por causa de sua simplicidade de código usando o recurso “BeautifulSoup”.
Ao usar esse recurso, você pode facilmente capturar ou extrair os dados em menos tempo em comparação com qualquer outra linguagem de programação. Ele também contém algumas linhas de códigos em Python, enquanto a cópia de um site e seus pacotes de biblioteca padrão tornam o código fácil de escrever e entender. Basta escrever em Python:
pip instalar Beautifulsoup4Basicamente, BeautifulSoup analisa os dados em termos de código HTML na página da web. Agora é atualizado como “Beautifulsoup4”. Agora, “pip” é um módulo Python que executa a linha de comando que fornecemos.
Etapa 3: enviar solicitação de URL
Ao configurar o código do script, envie uma solicitação de URL para o site que você deseja copiar. Pois, se você não enviar uma solicitação de URL ou se esquecer de enviar por acaso, os dados não serão baixados. Ele vai lançar um erro na tela. Antes de enviar uma solicitação, limpe seu histórico de navegação, memória cache, cookies etc.
Etapa 4: não envie URLs para solicitar paralelamente
Se você enviar solicitações paralelamente, uma por uma, o site vai capturar seu mesmo endereço IP, o que o levará a “ Ataque de serviço de negação ” em seu site. Como resultado, uma ação difícil pode ser tomada pela pessoa proprietária do site ou seu endereço IP pode ser bloqueado. Portanto, faça seu movimento com sabedoria. Oculte seu proxy ou até mesmo altere-o de vez em quando.
Etapa 5: deixe seu rastreamento lento e trate bem o site
Para tratar bem o site, use uma função de aceleração que controla a velocidade de rastreamento automaticamente no carregamento do spider e no site. Você pode até ajustar a aranha para uma velocidade neutra depois que uma trilha é executada. Se você correr mais rápido o rastreamento, você obterá o pior resultado. Você deve adicionar algumas bibliotecas após rastrear um número mínimo de páginas da web e escolher o menor número de uma solicitação consistente, se possível. O Spider fica bem para todos os raspadores de teia quando você usa essas técnicas.
Etapa 6: Baixe os dados solicitados e execute o código do script
Nesta etapa, você baixará dados de todos os URLs. A ferramenta de raspagem buscará automaticamente os dados do site. Os dados solicitados serão convertidos de não estruturados para o conjunto de dados estruturados em um formato específico. É recomendável que execute seu código novamente depois de fazer qualquer alteração no script.
Nota: Tente fazer download de dados em links de URLs de pequena quantidade. Não envie solicitação de download para todos os URLs juntos.
Etapa 7: Divida os dados de raspagem em fases diferentes
Isso abrirá caminho para você se você dividir os dados de extração em uma fase menor. Vamos entender com um pequeno exemplo. Ao escolher um site para raspagem, divida o site em duas fases. Na primeira fase, reúna todos os links para a página da qual deseja extrair dados. Na segunda fase, baixe as páginas da web para copiar o conteúdo.
Etapa 8: Armazenamento para URL
Vamos supor que você baixou dados de até 75% e, depois disso, sua raspagem falhou ou parou por algum motivo técnico. Então, o que você faria para terminar o restante dos 25% de dados? Se acontecer, definitivamente, você perderá muito tempo. Portanto, faça uma lista permanente de URLs em um banco de dados.
Como fazer um web scraping? O passo a passo!
Parte 1: Ideia Geral – O que você deseja fazer?
Responda às seguintes perguntas primeiro:
- O que eu quero saber?
- Que informações podem me dar a resposta?
É importante identificar o problema que você está procurando resolver por meio de web scraping como sua primeira etapa.
Exemplo:
Problema : Adoro frutas tropicais, mas elas são caras.
Solução de web scraping : Eu acompanho os preços das frutas importadas, para descobrir quando e onde as encontro mais barato.
Se você pessoalmente não tem um problema, pense em um problema que outras pessoas possam ter e que você possa resolver.
Parte 2: Identifique os sites onde seus dados estão
Agora que você sabe aproximadamente o que deseja resolver e como vai resolvê-lo, precisará encontrar a fonte dos dados.
Encontre uma boa fonte que tenha muitas informações e, especificamente, as informações-chave que você está procurando.
EXEMPLO:
Meu amor por frutas importadas e minha busca por opções mais baratas significa que preciso de um site que tenha preço e minhas frutas tropicais favoritas.
Parte 3: Obtenha seus dados – analisando os dados do HTML
Agora estamos realmente entrando em web scraping. Portanto, a chave para começar assim que você tiver um problema e seu site é acessar o HTML do site para localizar os dados.
HTML é a linguagem que define a estrutura do conteúdo de um site. Cada site tem toda a sua estrutura de conteúdo escrita em seu código HTML.
Você pode encontrar o código HTML de cada site:
- Chrome : Personalizar → Mais ferramentas → Ferramentas do desenvolvedor
- Safari : clique com o botão direito + Mostrar código-fonte da página
- Firefox : pressione Alt + Ferramentas → Desenvolvedor da Web → Código-fonte da página
- Microsoft Edge : Mais ícone → Ferramentas do desenvolvedor
- Internet Explorer : pressione Alt + Exibir → Código-fonte
Vá em frente e tente encontrar o código HTML de qualquer site de sua preferência.
Esta é a aparência do código-fonte da página HTML da Netflix:
O objetivo da análise é essencialmente escolher as coisas realmente boas, dados úteis e valiosos, e deixar todo o resto dos dados desnecessários.
EXEMPLO:
Por amor pelas frutas tropicais, precisaríamos especificamente analisar os preços das frutas e os nomes das frutas associadas a esses preços.
A análise de dados pode consistir em vários métodos diferentes, dependendo da aparência da origem da página e de como ela está configurada.
A ideia final é que você identifique padrões específicos no HTML para extrair os dados relevantes. Mas, visto que o padrão de código é diferente para todos os sites, é uma técnica muito caso a caso.
Parte 4: Definir um valor de referência (opcional)
Agora que analisamos os dados, precisamos configurar um sistema que nos alerte sempre que encontrarmos algo que estamos procurando.
Um valor de referência é uma etapa opcional, mas é desejável defini-lo apenas para garantir que haja algo para comparar os valores.
Existem dois tipos de valores de referência:
Estático : preço médio da “pêra portuguesa” durante todo o ano — sempre o mesmo valor
Dinâmico : mudanças ao longo do ano — preço médio da loja
Especificamente, quando procuro frutas importadas, quero um valor de referência que seja ajustado com base na estação em que estamos.
Obviamente, as frutas são mais baratas no verão e mais caras no inverno; então, se quisermos tê -las o ano todo, precisamos saber quando a fruta é mais barata no inverno e quando é a mais barata no verão. Portanto, precisamos de valores de referência que variam de acordo com as estações.
Parte 5: Definir um valor de gatilho
Agora vem a parte importante: definir um valor de disparo. Um valor de gatilho é um valor que você escolhe e é ‘ativado’ sempre que algo específico acontece.
Se você tiver um valor de referência, seu valor de acionamento será determinado com base no valor de referência que você definiu. Pode ser uma porcentagem do número de referência (como 30% a menos) ou um número absoluto (como R$3).
EXEMPLO:
Se meu valor de referência no verão for R$3, o valor de acionamento pode ser R$2. Isso significa que toda vez que a fruta cai para menos de R$2 no preço no verão, eu recebo a notificação. No inverno, no entanto, talvez meu valor de referência seja R$4, então meu valor de gatilho é R$3.
Parte 6: Notificações
Agora que você tem os dados e os valores de acionamento, precisa haver uma notificação. Você precisará descobrir um meio que será capaz de enviar as informações para que você saiba que algo aconteceu!
Há uma grande variedade de exemplos, dependendo de sua preferência: telefonema, e-mail, texto, ou você pode abusar da criatividade e postar automaticamente no Twitter, por exemplo.
Parte 7: cronômetro em seu script
Depois de ter quase tudo configurado, é hora de informar o programa com que frequência você deseja que ele seja executado. Também existem muitas opções aqui, dependendo do que exatamente você está procurando. Se você está procurando preços de frutas importadas, pode não ser muito útil operá-lo 24 horas por dia, 7 dias por semana, só porque os preços não são atualizados por hora.
Para preços de frutas,provavelmente executaríamos o código uma vez por dia para ter certeza de que estamos recebendo atualizações suficientes.
Parte 8: Configurar o Script para Executar Automaticamente
Finalmente, a última etapa seria configurar o código para que seja executado sozinho. Você não quer ter que ir ao seu computador todos os dias e clicar em ‘Executar’ no seu programa. Isso é uma perda de tempo.
Para configurá-lo para ser executado automaticamente, você pode, por exemplo, codificar para que o programa seja executado ‘toda vez que o computador for inicializado’ ou para que ele seja executado ‘sempre às 11h’.
Por que Python é usada para fazer web scraping?
Python é usado principalmente para web scraping, pois é muito simples de começar. Não apenas a sintaxe é bastante simples de entender, mas também existem comunidades Python prósperas que podem ajudar as pessoas iniciantes a se tornarem proficientes com esta linguagem de programação. Além disso, Python carrega uma extensa coleção de bibliotecas que auxiliam na extração e manipulação de dados.
Alguns exemplos de bibliotecas Python usadas para fins de web scraping são Beautiful Soup, Scrapy e Selenium, que são fáceis de instalar e usar. Existem outras bibliotecas Python também, como Pandas e Numpy, que podem ser usadas para lidar com dados recuperados da Internet.
Como fazer um web scraping Python? Tutorial!
Nesta demonstração, vamos percorrer nosso primeiro projeto de web scraping em Python. Estaremos copiando a página da Wikipedia para buscar a Lista de bilionários indianos publicada pela Forbes no ano de 2018. Podemos buscar a Lista de bilionários mesmo depois que ela for atualizada para o ano de 2021 com a ajuda do mesmo programa de web scraping Python.
Etapa 1: busque a página da web e converta a página html em texto com a ajuda da biblioteca de solicitações Python
#import the python request library to query a website
import requests
#specify the url we want to scrape from
Link = "https://en.wikipedia.org/wiki/Forbes_list_of_Indian_billionaires"
#convert the web page to text
Link_text = requests.get(Link).text
print(Link_text)Saída:

Etapa 2 : Para obter informações úteis, converta Link_text (que é do tipo string) no objeto BeautifulSoup . Importe a biblioteca BeautifulSoup do bs4
#import BautifulSoup library to pull data out of HTML and XML files
from bs4 import BeautifulSoup
#to convert Link_text into a BeautifulSoup Object
soup = BeautifulSoup(Link_text, 'lxml')
print(soup)Saída:

Etapa 3: com a ajuda da função prettify () , faça o recuo adequado
#make the indentation proper
print(soup.prettify())Saída:
Etapa 4: para buscar o título da página da web, use soup.title
#Para dar uma olhada no título da
impressão da página da web print(soup.title)Saída: A primeira tag de título será fornecida como uma saída.
Forbes list of Indian billionaires - Wikipedia Etapa 5: queremos apenas a parte da string do título, não as tags
#Somente a string, não as tags
impressas
print(soup.title.string)Saída:
Forbes list of Indian billionaires - WikipediaEtapa 6: também podemos explorar tags no objeto sopa
#First tagsoup.aResultado: a primeira tag pode ser vista aqui.
Etapa 7: explore todas as tags
#all the tags
soup.find_all('a')Saída:
Etapa 8: Novamente, da mesma forma que buscamos as tags de título, buscaremos todas as tags da tabela
#Fetch todas as tags da tabela
all_table = soup.find_all ('table')
print (all_table)Saída:
Etapa 9: Como nosso objetivo é obter a Lista de Bilionários da página wiki, precisamos descobrir o nome da classe da tabela. Vá para a página da web. Inspecione a tabela colocando o cursor sobre ela e inspecione o elemento usando ‘Shift + Q’.
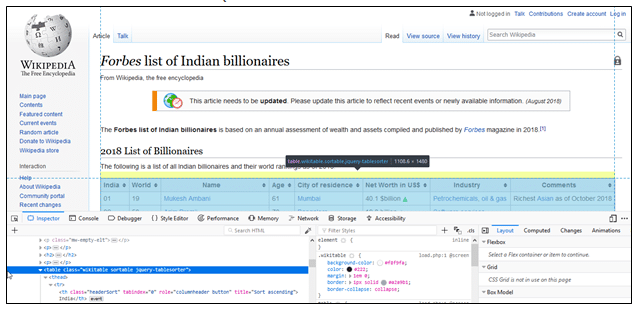
Portanto, nosso nome de classe de tabela é ‘classificável por wikit’ . Vamos seguir em frente e buscar a lista.
Etapa 10: agora, busque todas as tags de tabela com o nome de classe ‘wikitable sortable’
#fetch todas as tags de tabela com nome de classe = "wikitable sortable"
our_table = soup.find ('table', class_ = 'wikitable sortable')
print (our_table)Saída:
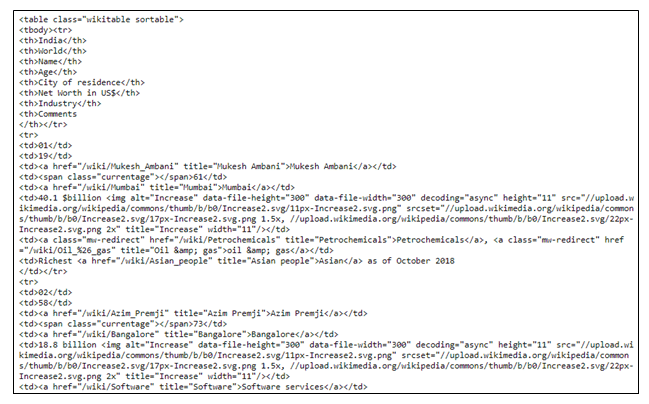
Etapa 11: podemos ver que as informações que desejamos recuperar da tabela contêm tags. Portanto, encontre todas as tags de table_links .
table_links = our_table.find_all('a')print(table_links)Saída:

Etapa 12 : para colocar o título em uma lista, itere sobre table_links e anexe o título usando a função get ()
#put the title into a list
billionaires = []
for links in table_links:
billionaires.append(links.get('title'))
print(billionaires)Saída:

Etapa 13: Agora que temos nossos dados necessários na forma de uma lista, usaremos a biblioteca Python Pandas para salvar os dados em um arquivo Excel. Antes disso, temos que converter a lista em um DataFrame
#Converta a lista em um dataframe
import pandas como pd
df = pd.DataFrame (bilionários)
print (df)Saída:

Etapa 14: use o seguinte método para gravar dados em um arquivo Excel.
#Para salvar os dados em um arquivo Excel
writer = pd.ExcelWriter ('indian_billionaires.xlsx', engine = 'xlsxwriter')
df.to_excel (writer, sheet_name = 'List')
writer.save ()Agora nossos dados foram salvos em uma pasta de trabalho do Excel com o nome ‘indian_billionaires.xlsx’ e dentro de uma planilha chamada ‘List’.
Etapa 15: apenas para ter certeza se a pasta de trabalho do Excel foi salva ou não, leia o arquivo usando read_excel
#verifique se foi feito corretamente ou não
df1 = pd.read_excel ('indian_billionaires.xlsx')
df1Saída:

Parabéns! Criamos com sucesso nosso primeiro programa de web scraping.
Qual a relação entre web scraping e big data?
Análise de Big Data, aprendizado de máquina, indexação de mecanismo de pesquisa e muitos outros campos de operações de dados modernos exigem rastreamento e extração de dados. A questão é que não são as mesmas coisas!
É importante entender desde o início que a extração de dados é um processo específico que pode acontecer em qualquer lugar — na web, no banco de dados local, em qualquer base de registros ou planilhas. Mais importante, a coleta de dados às vezes pode ser feita manualmente.
Muito pelo contrário, o rastreamento de dados da web é um processo de mapeamento de todos os recursos online específicos para posterior extração de todas as informações relevantes. Deve ser feito por crawlers especialmente criados (robôs de busca) que seguirão os URLs, indexando os dados essenciais nas páginas e listando todos os URLs relevantes que encontra ao longo do caminho.
Quais dados o scraping pode acessar?
O scraping consegue acessar informações da Web em formato HTML. Com essa técnica de programação, a gente consegue extrair informações de páginas (websites) e transformamos dados não estruturados (HTML) em dados estruturados (Banco de dados, JSON ou planilha).
Quais os riscos do scraping para quem tem os dados coletados?
Apesar de não haver consequências aparentes para pessoas proprietárias de sites, a prática de Scraping pode, a longo prazo, levar à criação de brechas no sistema, o que pode levar a ciberataques ou tentativas de phishing. Afinal, muita informação importante pode ser conseguida por meio do Scraping.
Como se proteger dos riscos do scraping?
Primeiro, as empresas precisam tomar medidas legais contra os raspadores de dados, alertando-os contra o processo (você pode incluir o idioma em seus termos de serviço). Outros procedimentos de segurança incluem a lista negra e a lista branca de endereços IP, configurando o acesso contra scraping e evitando hot linking.
A segurança de endpoint pode oferecer várias outras ferramentas contra scraping, como controle de aplicativos e prevenção contra perda de dados. No entanto, as empresas também devem usar o monitoramento de dados para avaliar quais informações podem ser facilmente eliminadas. Além disso, requer avaliação de terceiros, incluindo seu acesso e suas interações de dados.
As estratégias comuns de proteção anti-rastreador incluem:
- Monitorar contas de usuário novas ou existentes com altos níveis de atividade e sem compras
- Detecção de volumes anormalmente altos de visualizações de produtos como um sinal de atividade não humana
- Rastrear a atividade dos concorrentes em busca de sinais de correspondência de preço e catálogo de produtos
- Aplicar termos e condições do site que impeçam a invasão mal-intencionada da web
- Empregar recursos de proteção de bot com análise comportamental profunda para identificar bots ruins e evitar web scraping
Pessoas proprietárias de sites normalmente usam arquivos “robots.txt” para comunicar suas intenções quando se trata de scraping. Os arquivos Robots.txt permitem que os robôs de scraping percorram páginas específicas; no entanto, os bots mal-intencionados não se importam com os arquivos robots.txt (que servem como um sinal de “não invasão”).
Web scraping é crime?
Bem, essa é uma das perguntas mais comuns que surgem quando se trata de web scraping (também conhecido como data scraping). A resposta não pode ser resumida em uma palavra. Nem todos os atos de web scraping são considerados legais. Os serviços de scraping da Web em Python que extraem dados disponíveis publicamente são legais . Mas, às vezes, pode causar problemas jurídicos, da mesma forma que qualquer ferramenta ou técnica no mundo pode ser usada para o bem ou para o mal.
Por exemplo, a coleta de dados não públicos na web, que não são acessíveis a todos na web, pode ser antiética e também pode ser um convite para problemas legais. Portanto, é aconselhável evitar fazer isso.
Para realizar uma raspagem ética na web, os web scrapers precisam seguir algumas regras. Vamos discuti-los antes de vasculhar a web.
Regras Python Web Scraping:
Antes de começarmos a vasculhar a web, existem algumas regras que devemos seguir para evitar problemas legais. Eles são:
- Verifique os Termos e Condições do site antes de retirá-lo. A seção Uso legal de dados terá as informações sobre os dados que todos nós podemos usar. Normalmente, os dados que coletamos não devem ser usados para fins comerciais.
- Use apenas conteúdo público.
Quanto custa um web scraping?
Em primeiro lugar, o custo de web scraping depende de vários fatores. Não há custo único para web scraping. Você deve:
- 1) compreender cada método de raspagem;
- 2) considere certos fatores ao selecionar um método de web scraping.
Compreender a estrutura de custos de cada método de web scraping
Há uma variedade de maneiras pelas quais uma empresa pode realizar a remoção da web. Eles podem escolher uma das seguintes opções.
Para uma empresa que não dispõe de pessoal técnico necessário para a extração de dados, pode optar pelos serviços de entidades externas. Esses órgãos externos podem ser freelancers em sites como o Upwork ou contratar uma equipe, geralmente uma empresa especializada em web scraping.
Se não quiser terceirizar seu projeto de web scraping, você pode usar uma ferramenta de web scraping para criar um raspador. As ferramentas de web scraping são softwares especialmente projetados para coletar e agrupar dados online.
Algumas das principais ferramentas de web scraping disponíveis são:
1. Octoparse
O Octoparse é fácil de usar e, mais importante, os dados copiados podem ser baixados em diferentes formatos.
O plano gratuito é ótimo, mas tem muitas limitações. Se você quiser mais, opte por um plano pago. Os planos pagos são o plano padrão ($75 por mês), o plano profissional ($209 por mês) e o plano empresarial ($4.899 por ano).
2. ParseHub
Muitas pessoas profissionais de web scraping usam o ParseHub porque é muito eficiente na extração de dados de sites complexos. Embora o plano gratuito seja bastante limitador, ainda é uma excelente escolha para quem quer experimentar a raspagem de teia.
Os outros planos de preços incluem o plano padrão ($149 por mês), o plano profissional ($499 por mês) e o plano empresarial (fornecerão uma cotação quando você entrar em contato com eles).
3. Mozenda
Esta é uma das ferramentas de web scraping amplamente utilizadas, com três planos de preços à sua escolha. Tem o plano de projeto ($ 250 por mês para 1 usuário), o plano profissional ($ 350 por mês para dois usuários) e o plano empresarial ($ 450 por mês para 3 usuários).
Se o custo de web scraping e os recursos do Mozenda estiverem dentro do seu orçamento, você pode considerar usá-lo.
4. Raspador
Esta é uma ferramenta de extensão do Google Chrome que pode ser usada para extração de dados simples. Deve ser eficaz o suficiente para projetos simples de web scraping com uma pequena quantidade de dados. É um raspador de tela gratuito e fácil de usar que pode extrair dados de tabelas online e fazer upload dos resultados para o Google Docs.
Se você deseja uma ferramenta de pesquisa online simples e gratuita, o Scraper é uma boa escolha.
5. import.io
Este software de web scraping é tão eficiente quanto econômico. Com três planos de preços: o plano essencial ($299 por mês), o plano essencial anual ($1999 anual) e os planos premium (a empresa especificará o preço com base em suas necessidades), o import.io é uma das ferramentas de web scraping mais rápidas.
O processo de coleta de dados é suave e contínuo. Ele possui uma série de recursos interessantes que o ajudarão em seu projeto de web scraping.
Se você não consegue passar pelo estresse ou pela curva de aprendizado de criar um raspador, pode facilmente optar por um serviço de dados gerenciado. Tudo o que você precisa fazer é fornecer ao provedor de serviços de web scraping os sites que você deseja copiar e eles fornecerão todos os dados de que você precisa. Ou seja, você não precisa perder tempo aprendendo as cordas do software.
Todas as ferramentas de web scraping de que falamos, excluindo o Scraper, oferecem esse serviço. O custo de web scraping depende de suas necessidades. Você teria que entrar em contato com o provedor de serviços de web scraping para obter uma cotação de quanto custará. Normalmente, o preço começa em $ 399.
Faça algumas considerações finais a partir deste material se, para você, sua empresa ou a empresa para a qual trabalha, o web scraping é vantajoso ou não.
Obviamente, não existem técnicas ou produtos perfeitos. Mas o que essas informações podem nos ajudar é a melhorar constantemente a nós mesmos e as coisas que construímos e aproveitar ao máximo o que a Internet tem a oferecer.
Gostou de aprender sobre Scraping? Agora, continue aprendendo em nosso blog, agora sobre Spoofing, o que é e como se proteger!


