
A inteligência artificial (IA) tem como uma de suas proposições a ideia de que os humanos consigam se comunicar com as máquinas. No entanto, isso atualmente é impossível já que as nossas linguagens não são compatíveis. A NLP ou PNL surge para tentar resolver essa situação.
Para entendermos melhor sobre o NLP, precisamos entender como funciona o processamento de uma linguagem e se é possível que o computador a emule. Fique com a gente e confira:
- O que é NLP?
- Como funciona o NLP na prática?
- Conheça a pirâmide do Processamento de Linguagem Natural!
- Qual a importância do contexto, intenção e sentimento para o NLP?
- Qual a importância das redes neurais e do aprendizado de máquina para o NLP?
- Quais os 4 tipos de abordagem do processamento NLP?
- Quais as vantagens do NLP?
- Quais os principais desafios do NLP?
- Conheça os principais termos do NLP
- Quais as principais técnicas usadas no NLP?
- Quais as 5 principais aplicações do NLP?
- 3 exemplos de NLPs na prática!
O que é NLP?
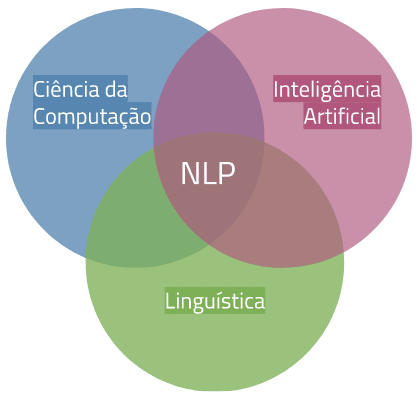
NLP é o termo em inglês que significa Processamento de Linguagem Natural, ou também PNL. Essa é uma das áreas que une a Ciência da Computação, Linguística e Inteligência Artificial, todas com o mesmo propósito de compreender e realizar interpretações das linguagens humanas.
Desta maneira, com o auxílio de todas as ferramentas da inteligência artificial, é possível criar um aprendizado de máquina que realize traduções, reconhecimento de voz e até classificação de tópicos textuais. Resumidamente, o NLP é a conexão da fala humana com a computacional.
Essa tecnologia utiliza diversos outros conceitos que se enquadram nela como uma subcategoria. Por exemplo, algumas áreas bastante pesquisadas dentro de NLP são o Entendimento de Linguagem Natural (NLU) e a Geração de Linguagem Natural (NLG). Como os nomes sugerem, ambas partes são responsáveis por etapas diferentes do processamento da linguagem humana.
Como funciona o NLP na prática?
O NLP é treinado com aprendizado de máquina, sendo esse um ramo da inteligência artificial que utiliza de grandes quantidades de dados e tempo para treinar algoritmos que consigam realizar previsões em determinados assuntos. No caso da PNL, as máquinas são treinadas para entender a nossa linguagem. Nenhum conhecimento é desperdiçado no processo e as máquinas ficam mais inteligentes com o tempo.
Pré-processamentos
Aqui estão as etapas comuns de pré-processamento que uma máquina de PNL usará.
- Tokenização: A tokenização é um processo para separar cada palavra de um documento em pequenas partes (chamadas de tokens). Os tokens são fundamentais para que o software determine quais palavras estão realmente presentes e possa evoluir cada vez mais no processamento da linguagem natural.
- Stemização e Lematização: Os dois processos são bem semelhantes e têm como resultado a simplificação de palavras como “Correndo” para apenas “correr”. Essa prática torna o processamento da linguagem mais rápido e simples para todas as máquinas de inteligência artificial.
A stemização é mais rápida e envolve a remoção de quaisquer afixos de uma palavra. Os afixos são adições ao início e ao fim da palavra que lhe dão um significado ligeiramente diferente. Como a palavra, “voar” se torna “voa” a partir da remoção do seu afixo.
Com tudo, em alguns casos, a derivação pode acabar resultando em erros quando palavras semelhantes têm algum significado diferente. Consideramos as palavras “nadar” e “nada”. Com a stemização conseguimos reduzir “nadar” para “nada” e temos significados completamente diferentes.
A lematização é muito mais complicada porém funcional. Aqui buscamos reduzir a palavra para o seu lema, que seria a forma mais básica possível, como “Voando” para “voa“. Desta forma, a lematização utiliza o contexto e o dicionário para realizar análises morfológicas de todas as palavras, com isso também, a tarefa acaba se tornando bem mais lenta.
Por fim, para compararmos os dois, na stemização conseguimos reduzir a palavra “correndo” para “cor”, enquanto que na lematização temos o resultado preciso de “correr”.
Processamentos
A partir do pré-processamento de um texto, é possível realizar alguns processamento na linguagem natural.
- Análise de Sentimento: A tarefa de avaliação do sentimento de uma frase, buscando encontrar a conotação do texto.
- Classificação do Tópico: Ferramenta para encontrar o assunto do texto. A máquina de PNL consegue identificar os assuntos de um documento a partir de diversas técnicas.
- Detecção de Intenção: O processo de detecção da intenção de um texto é fundamental para garantir uma melhor comunicação e confiança do cliente.
- Part-of-Speech Tagging: O tagueamento ocorre em todas as palavras de um texto, cada token, assim chamado, tem um valor de verbo, advérbio, substantivo, etc.
- Reconhecimento de Fala: A conversão de fala para texto é uma das outras tarefas do PNL e só é possível com muito treinamento e aprendizado da máquina, já que temos muitas diferenças nas falas e várias entonações.
- Reconhecimento de entidade nomeada: Aqui, a tarefa é fazer a máquina compreender qual o significado de uma entidade e até quais são palavras parecidas. Algo como, “Rainha” é parecido com “Menina“.
- Geração de linguagem natural: Como o próprio nome já indica, é a geração de texto automático a partir de uma máquina de processamento de linguagem natural. É usado majoritariamente em chats bots.
Conheça a pirâmide do Processamento de Linguagem Natural!
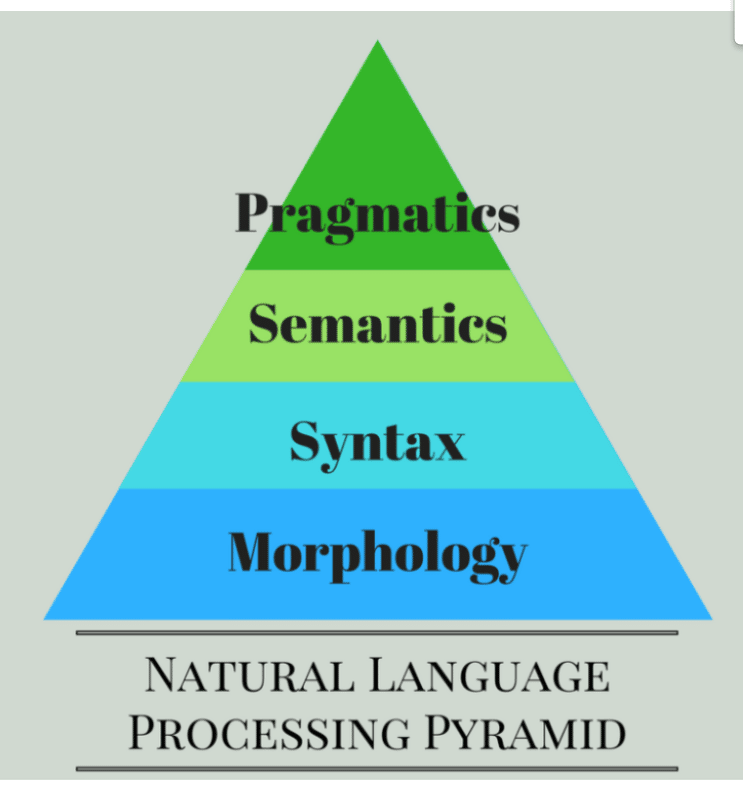
Pragmática
Na pragmática, devemos entender os objetos e os eventos que estão alocados na frase, a partir de um determinado contexto. Por exemplo, se analisarmos a frase “Não é permitido entrar na loja de chapéu“, podemos interpretá-la de duas maneiras: a primeira é que não é permitido entrar em determinada loja usando um chapéu, no outro caso, não é permitido a entrada em uma loja que vende chapéus. No entanto, é evidente que uma das sentenças faz mais sentido que a outra.
O pragmatismo é muito importante para entender a linguagem natural e é papel da pessoa desenvolvedora aplicar regras parecidas no desenvolvimento de um software que necessita disso.
Semântica
A semântica é fundamental para que uma frase não perca totalmente o seu sentido. O analisador de palavras deve entender que um objeto não pode ter certos adjetivos, por exemplo, um “sorvete quente” não deveria ser aceito, pois naturalmente não é possível que exista um sorvete realmente quente.
O contexto aqui é que a palavra deve seguir rigidamente o significado que está no dicionário.
Sintaxe
Nesse campo, podemos lembrar da sintaxe que temos nas linguagens de programação, o significado é semelhante Neste caso, temos que ter uma frase que tenha uma ordem de palavras corretas, formando um contexto verdadeiro.
Uma frase como “A casa voltou para as pessoas” não pode ser aceita pelo analisador dessa fase.
Morfologia
Aqui temos uma fase que é um pouco mais complexa mas que também é muito importante para um todo. Na entrada de uma palavra, criamos tokens referentes aos seus parágrafos, frases e palavras. Por exemplo, uma palavra como “inquieto“, pode ser dividida em dois subconjuntos de tokens como “in-quieto“, sendo “quieto” a raiz da palavra, e “in” um afixo.
Qual a importância do contexto, intenção e sentimento para o NLP?
Cada vez mais seguimos no automático e nem sempre percebemos como as nossas frases estão cheias de intenções, sentimentos e um contexto específico. Para a máquina, entender tudo isso é muito complicado e, de início, impossível.
Por causa disso, a inteligência artificial precisa compreender todo o significado real e oculto das frases que ditamos. Para isso, o treinamento do aprendizado de máquina se faz muito necessário.
Os dois principais elementos de uma conversação são a intenção e a entidade. Sendo que a intenção é o objetivo real da conversa, como por exemplo, quando queremos mais informações de um pedido de e-commerce, falamos para o bot algo como “Mais informações do meu pedido” e ele consegue compreender corretamente.
Já a entidade é uma solicitação que está oculta em uma frase. Se falarmos algo como “Quero informações de um pedido“, é provável que a inteligência artificial consiga detectar a palavra “pedido” e realizar o atendimento correto.
O uso de máquinas para o atendimento do grande público em geral é muito importante para que esses algoritmos possam evoluir e aprender cada vez mais contextos regionais, como o uso de gírias e abreviações.
Como podemos ver, todo o contexto importa e a compreensão disso para as máquinas é essencial para que possamos dar o próximo passo na evolução do processamento da linguagem natural.
Qual a importância das redes neurais e do aprendizado de máquina para o NLP?
Redes neurais são ideais para resolver problemas em que a sequência é mais importante do que os próprios itens individuais.
Uma rede neural artificial simula a rede neural biológica do nosso cérebro, com isso, é possível realizar um maior aprendizado e processamento em várias áreas do aprendizado de máquina. A ideia de simulação abrange todo o conjunto de neurônios e as suas ligações neurológicas.
A rede neural também tem um bom desempenho com:
- Rotulagem de sequência
- Classificação de texto de processamento de linguagem natural (NLP)
- Geração de texto de processamento de linguagem natural (NLP)
Além disso, o aprendizado de máquina para PNL e análise de texto envolve um conjunto de técnicas estatísticas para identificar partes do discurso, entidades, sentimento e outros aspectos do texto. As técnicas podem ser expressas como um modelo que é então aplicado a outro texto, também conhecido como aprendizado de máquina supervisionado.
Também pode ser um conjunto de algoritmos que funcionam em grandes conjuntos de dados para extrair significado, o que é conhecido como aprendizado de máquina não supervisionado. É importante entender a diferença entre aprendizado supervisionado e não supervisionado e como você pode obter o melhor de ambos em um sistema.
Quais os 4 tipos de abordagem do processamento NLP?
O processamento de linguagem natural, no entanto, é mais do que apenas análise de fala. Há uma variedade de abordagens para o processamento da linguagem humana.
Simbólica
A abordagem simbólica ao processamento de linguagem natural é baseada em regras e léxicos desenvolvidos pela humanidade. Em outras palavras, a base dessa abordagem está nas regras de fala geralmente aceitas dentro de uma determinada língua que são materializadas e gravadas por pessoas linguistas para os sistemas computacionais seguirem.
Estatística
A abordagem estatística para processamento de linguagem natural é baseada em exemplos observáveis e recorrentes de fenômenos linguísticos. Modelos baseados em estatísticas reconhecem temas recorrentes por meio da análise matemática de grandes corporações de texto. Ao identificar tendências em grandes amostras de texto, o sistema de computador pode desenvolver suas próprias regras linguísticas que serão usadas para analisar entradas futuras e/ou a geração de saídas de linguagem.
Conexionista
A abordagem conexionista do processamento de linguagem natural é uma combinação das abordagens simbólica e estatística. Essa abordagem começa com regras de linguagem geralmente aceitas e as adapta a aplicações específicas a partir de entradas derivadas de inferência estatística.
Híbrida
A abordagem híbrida combina o melhor das abordagens baseadas em regras e aprendizado de máquina com processamento de linguagem natural. A experiência humana fornece orientação para análises precisas e o aprendizado de máquina ajuda a dimensionar a análise com facilidade.
O aprendizado de máquina pode ajudar ainda mais a reduzir o esforço de construção de modelo humano, aproveitando o aprendizado semi supervisionado para automatizar os dados de marcação com base na entrada humana para seus dados de treinamento. Essa abordagem pode ser construída sem um grande conjunto de dados de treinamento.
Quais as vantagens do NLP?
Vamos dar uma olhada nas principais vantagens do NLP:
- Fazer análises em larga escala
- Obter uma análise mais objetiva e precisa
- Simplificar processos e reduzir custos
- Melhorar a satisfação de clientes
- Entender melhor o seu mercado
- Capacitar seus funcionários
- Obter insights reais e acionáveis
Quais os principais desafios do NLP?
O domínio da NLP relata grandes avanços na medida em que vários problemas, como marcação de parte da fala, são considerados totalmente resolvidos. Ao mesmo tempo, tarefas como sumarização de texto ou sistemas de diálogo de máquina são notoriamente difíceis de decifrar e permanecem abertas nas últimas décadas.
No entanto, se olharmos mais profundamente para essas tarefas, veremos que os problemas por trás delas são bastante semelhantes e se dividem em dois grupos:
- Relacionado a dados
- Relacionado ao entendimento
Até os dias atuais, o problema de entender a linguagem natural continua sendo o mais crítico para dar mais sentido e processamento do texto.
As questões ainda não resolvidas incluem encontrar o significado de uma palavra ou um sentido de palavra, determinar escopos de quantificadores, encontrar referentes de anáfora, a relação de modificadores com substantivos e identificar o significado de tempos para objetos temporais.
Representar e inferir o conhecimento do mundo, e o conhecimento comum em particular, também é difícil. Além disso, permanecem desafios na pragmática: uma única frase pode ser usada para informar, mentir sobre um fato ou a crença da pessoa falante sobre ele, chamar a atenção, lembrar, comandar, etc. A interpretação pragmática parece ser aberta e difícil de ser aprendida por máquinas.
Conheças os principais termos do NLP

1. Corpus
Em linguística e PNL, corpus (literalmente latim para corpo) refere-se a uma coleção de textos. Tais coleções podem ser formadas por um único idioma de textos, ou podem abranger vários idiomas. Existem inúmeras razões pelas quais corpora (o plural de corpus) pode ser útil. Corpora também pode consistir em textos temáticos (históricos, bíblicos, etc.). Corpora são geralmente usados apenas para análise linguística estatística e teste de hipóteses.
2. Tokenization ou Tokenização
A tokenização é, geralmente, uma etapa inicial no processo de NLP, uma etapa que divide cadeias de texto mais longas em pedaços menores, ou tokens. Grandes pedaços de texto podem ser tokenizados em sentenças, sentenças podem ser tokenizadas em palavras, etc. O processamento adicional geralmente é realizado após um pedaço de texto ter sido devidamente tokenizado.
3. Normalization ou Normalização
Antes do processamento adicional, o texto precisa ser normalizado. A normalização geralmente se refere a uma série de tarefas relacionadas destinadas a colocar todo o texto em igualdade de condições: converter todo o texto para o mesmo caso (maiúsculo ou minúsculo), remover pontuação, expandir contrações, converter números em seus equivalentes de palavras e assim por diante. A normalização coloca todas as palavras em pé de igualdade e permite que o processamento prossiga uniformemente.
4. N-grams
N-grams é outro modelo de representação para simplificar o conteúdo da seleção de texto. Ao contrário da representação sem ordem do conjunto de palavras, a modelagem de n-gramas está interessada em preservar sequências contíguas de N itens da seleção de texto.
5. Lexicons ou Léxicos
Léxicos se referem ao componente de um sistema de NLP que contém informações (semânticas, gramaticais) sobre palavras individuais ou sequências de palavras.
6. Pré processamento e limpeza dos dados
O pré-processamento de dados é uma etapa essencial na construção de um modelo de Machine Learning e depende de quão bem os dados foram pré-processados; os resultados são vistos.
Na PNL, o pré-processamento de texto é o primeiro passo no processo de construção de um modelo.
Quais as principais técnicas usadas no NLP?
No processamento da linguagem natural, possuímos algumas habilidades que são úteis na hora de identificar o significado das frases.
Stop Words
Stop Words são palavras comumente utilizadas em uma linguagem, no caso do português,
“a“, “ainda“, “algo“, entre muitas outras. As Stop Words também podem ser encontradas na mineração de dados e é usada principalmente para remover palavras que não agregam muito valor a uma frase. A ideia aqui, é economizar recurso na hora do processamento.
Stemming
O stemming (stemização, em português) é uma técnica utilizada para encontrar a stem (raíz) de uma palavra, por exemplo, a palavra Voando é associada a palavra Voar. A principal lógica deste algoritmo é o ato de cortar as palavras para tentar encontrar a sua base, em alguns casos dá certo, em outros nem tanto. Em nosso exemplo, a palavra Voando se transformaria em Voa, uma palavra muito semelhante ao que gostaríamos de ter.
Lemmatization
A lemmatization (lematização, em português) é uma outra técnica de reconhecimento de palavras, que utiliza do auxílio de um dicionário para encontrar o seu lemma (lema). Com isso, temos um resultado muito próximo e muitas vezes melhor que o stemming. Além disso, por ser um recurso mais sofisticado, tende a levar mais tempo no processamento e é mais indicado para casos complexos.
Bag of words
O bag of words (saco de palavras, em português) é um modelo utilizado para simplificar a visualização de palavras de um texto. Ou seja, a partir de uma frase, conseguimos extrair e organizar todas as palavras que foram citadas e as suas respectivas vezes. Na frase:
“Roberta gosta de aprender sobre processamento de linguagem natural e o João também.”
Podemos organizar da seguinte maneira:
“Roberta”, “gosta”, “de”, “aprender”, “sobre”, “processamento”, “de”, “linguagem”, “natural”, “e”, “o”, “João”, “também”.
TF-IDF
TF-IDF é uma habilidade que busca o produto da Frequência do Termo e da Frequência Inversa do Documento. Essa pesquisa é feita em relação às palavras de um documento e na avaliação de relevância de uma palavra.
Sendo assim, um texto que contém uma palavra considerada “diferente” como Sol é classificado como sendo uma palavra provavelmente relevante do texto. Por outro lado, palavras mais comuns como conjunções (e, ou, etc) não são levadas em consideração.
Word Embeddings
O word embeddings (incorporação de palavras, em português) visa compreender a similaridade das palavras de um documento com base no peso do seu vetor. Por exemplo, a palavra Correr tem o peso inclinado para palavras semelhantes ou com significado parecido, como Correndo, Corre, Andando, etc. Essa semelhança pode ser utilizada em uma rede neural para descobrir várias palavras parecidas e até analogias.
Named Entity Recognition (NER)
Named Entity Recognition (reconhecimento de entidade nomeada, em português) é uma tarefa de identificação com categorização de entidades num texto. Esta entidade pode ser qualquer palavra ou junções de palavras que se referem consistentemente à mesma coisa.
As categorias são predeterminadas e as identidades são classificadas entre si. Por exemplo, um modelo NER consegue entender a palavra “Bolo” em um texto e classificá-lo como um “Doce”.
Parts-of-speech (POS) Tagging
Parts-of-speech Tagging (tagueamento de parte da fala, em português) é a habilidade de classificar as palavras de um texto em verbos, adjetivos, substantivos, advérbios, etc. Essa classificação depende do contexto da frase e de cada palavra.
Quais as 5 principais aplicações do NLP?
Embora temos como IA e NLP tornam a nossa mente muito criativa em relação a aplicações e dispositivos futurísticos, já temos muitos exemplos básicos e reais do nosso dia-a-dia do PNL. Aqui estão alguns deles.
Filtros de e-mail
Com o início nos filtros de spam, a PNL mostrou para que serve. Com o aprendizado de certas palavras e frases, as nossas caixas de entrada conseguem detectar quais mensagens são ou não spam. Um dos exemplos mais famosos de caixa de spam, é do e-mail da Google (Gmail). Neste sistema temos o aprimoramento da PNL e o uso mais sofisticado por palavras, frases, endereços de e-mail, etc.
A partir disso, o site consegue categorizar em três divisões de e-mail: principal, social e promocional, tudo isso entendendo o conteúdo.
Busca de resultados
A NLP exerce grande papel nos mecanismos de busca atuais. O principal papel é verificar o fluxo de pesquisas com termos semelhantes, e recomendar para as outras pessoas palavras parecidas.
O Google, a partir das letras que você digita, começa a interpretar e tentar formular ideias sobre o que você possivelmente está procurando. Além do mais, em textos completos, o mecanismo de busca analisa a frase completa e reconhece com alta precisão o que a pessoa usuária está querendo.
Texto preditivo
Novamente, o NLP se comporta muito bem com palavras e rótulos, formando assim previsões que podem ser muito poderosas. O preenchimento automático, a correção de palavras e até mesmo os textos preditivos são os exemplos mais comuns que vemos em nossos smartphones.
A base disso é aprender tanto com a pessoa usuária, como também coletar dados e informações de várias pessoas do mundo. Basicamente, o algoritmo aprende com você e consegue corrigir palavras e frases automaticamente.
Tradução de idiomas
Se pensamos em inteligência artificial, provavelmente pensamos na tradução dos idiomas, isso porque os tradutores têm um papel fundamental na evolução do PNL.
O princípio é básico: com palavras que servem como rótulos e conjunto de dados para a entrada e saída, basta que o algoritmo comece a treinar e entender as demandas das pessoas usuárias. Isso é, ao traduzir um texto de uma língua para outra, podemos adicionar sugestões e também adicionar feedbacks construtivos. Desta forma, melhoramos toda a construção de linguagem dos sites.
Análise de dados
Pessoas analistas de dados utilizam quase que diariamente os fluxos integrados de dados que o NLP oferece. O resultado é simples: uma tela com gráficos que mostra todas as informações que coletamos.
Além do aumento do nível de acessibilidade e nas análises das demais organizações, o mercado de trabalho e as pessoas desenvolvedoras de software também ganham com essa união.
A exemplo disso, os dados e números que ficam visuais são considerados mais inteligentes, oferecendo uma semântica interessante para a pessoa usuária. Com isso, temos uma abertura nas oportunidades de exploração dos dados e visualização de histórico nas informações referentes.
3 exemplos de NLPs na prática!
Pesquisa inteligente com Klevu
Com a PNL, o preenchimento automático não é a única maneira de as empresas atualizarem sua pesquisa no site.
Klevu é um provedor de pesquisa inteligente que é alimentado por NLP, mas também é autodidata. Funciona melhor para e-commerce porque aprende observando como os compradores interagem com a pesquisa na loja.
Além de fornecer a função básica de pesquisa de preenchimento automático, o Klevu adiciona automaticamente sinônimos contextualmente relevantes a um catálogo que pode resultar em 3x a profundidade dos resultados da pesquisa. O software também oferece pesquisa personalizada, oferecendo produtos com os quais os clientes interagem anteriormente ou produtos que estão em alta.
Tradução de textos com Lilt
O Lilt é uma ferramenta de tradução que se integra a outras plataformas, como software de suporte como o Zendesk, para tornar a comunicação através das barreiras linguísticas mais rápida e barata do que apenas com um tradutor humano.
A ferramenta, que foi desenvolvida por dois ex-engenheiros que trabalharam no Google Tradutor, não é totalmente automatizada, mas trabalha e aprende com um tradutor humano para se tornar mais eficaz ao longo do tempo.
Alexa Skills
A Alexa funciona de maneira semelhante aos bots de mensagens, exceto com um número quase ilimitado de habilidades possíveis. As empresas podem tirar proveito disso desenvolvendo suas próprias habilidades que se integram a seus produtos ou acessam seus serviços baseados em nuvem.
O site de desenvolvedores da Amazon se aprofunda nas maneiras pelas quais as empresas podem lucrar com a criação de uma habilidade Alexa, principalmente com a compra de conteúdo premium. Gal Shenar, um desenvolvedor de habilidades do Alexa, afirma ter uma taxa de conversão de upsell de 34% em uma de suas habilidades, o que é maior do que ele esperaria ver no celular.
A Amazon também recompensa financeiramente as pessoas desenvolvedoras que criam as habilidades mais envolventes, distribuindo dinheiro todo mês para aqueles que geraram o maior envolvimento de clientes em cada categoria qualificada.
O processamento de linguagem natural é utilizado amplamente nos dias de hoje, e isso se deve ao fato de ser uma tecnologia que além de nos auxiliar em diversas tarefas, seja profissionalmente como pessoalmente, também busca se aprimorar cada vez mais.
O foco principal da NLP é entender os textos escritos pelos seres humanos e tentar identificar padrões nas linguagens. Com isso, tornando atividades como tradução de idiomas, autopreenchimento de textos e filtro de mensagens muito mais fáceis.
Por isso, é fundamental entender que o NLP precisa de um processo encadeado para que ele possa entender a nossa linguagem, e dessa forma é interessante a união do aprendizado da máquina com redes neurais para tornar o processamento de linguagem natural uma ferramenta muito mais poderosa e útil.
Aprenda mais sobre NLP com a Linguagem R: o que é, para que usar e por que aprender?


