
Quem trabalha com inovação precisa estar atento à possibilidade de utilizar programas de código aberto. Isso porque além de serem mais personalizáveis, eles podem ser incorporados facilmente a vários ambientes, o que reduz o custo dos seus projetos. Se você necessita de uma solução para efetuar buscas em um abiente de big data e que faça parte dessa categoria, uma boa alternativa é o Elasticsearch.
Ele é uma solução de TI flexível e escalável, que consegue entregar dados de um banco quase em tempo real para as pessoas usuárias (ou seja, registros com um alto nível de atualização) e, com isso, aumentar a sua produtividade. Inclusive, para projetos que envolvem consultas a informações em grande quantidade, ele sempre deve ser considerado.
Quer saber mais sobre o Elasticsearch e como ele pode ajudar você a ter sucesso trabalhando com TI? Então, confira o post a seguir!
Neste conteúdo você aprenderá:
- O que é Elasticsearch?
- O Elasticsearch é um banco de dados?
- O que é o Elastic Stack?
- Quais os conceitos básicos do Elasticsearch?
- Como funciona o Elasticsearch?
- Por que usar o Elasticsearch?
- Quais as desvantagens do Elasticsearch?
- Onde usar o Elasticsearch?
- Quais as diferenças entre Splunk e Elasticsearch?
- Como usar o Elasticsearch? Tutorial com passo a passo!
- Como instalar o Elasticsearch em um container Docker?
- 3 exemplos de consultas e usos do Elasticsearch!
- Quais os principais comandos usados no Elasticsearch?
- 3 empresas que já usaram o Elasticsearch!
Boa leitura!
O que é Elasticsearch?
O Elasticsearch é uma ferramenta de código aberto criada para buscar e tratar uma grande quantidade de dados e que funciona como um banco de dados não relacional. Foi desenvolvido por Shay Bannon, que publicou a primeira versão da solução em 2010. Atualmente, ele é utilizado por startups e grandes empresas de inovação, como SoundCloud, Twitter, Google, GitHub e Yelp.
Baseado em tecnologias como a Apache Lucene e o Java, o Elasticsearch tem uma interface simples e estruturada com o apoio do HTTP e do JSON. Para ter a elasticidade necessária, o recurso funciona melhor quando distribuído em clusters. Assim, ele pode entregar a escalabilidade necessária para o trabalho com ferramentas de análise de dados baseadas em big data.
O Elasticsearch é um banco de dados?
Sim, o Elasticsearch é um banco de dados, porém ele é independente. Isso é, seu principal caso de uso é para pesquisar textos e números de consultas relacionadas, como agregações. Geralmente, não é recomendado usar o Elasticsearch como o banco de dados principal, pois algumas operações como a indexação (inserção de valores) são mais pesadas em comparação com outros bancos de dados.
Se for necessário, podemos utilizar o Elasticsearch junto com qualquer outro banco de dados, como o MongoDB ou MySQL, em que os outros bancos de dados conseguem atuar como o banco de dados primário e conseguimos sincronizar o Elasticsearch com ele para as partes “pesquisáveis” dos dados.
Devemos lembrar também que o Elasticsearch por si só é apenas uma ferramenta de pesquisa e análise RESTful distribuído, logo, o seu foco principal é armazenar apenas o dados para a sua pesquisa, e não outros dados de um outro sistema.
O que é o Elastic Stack?
O Elastic Stack ou ELK Stack é um grupo de quatro produtos de código aberto, Elasticsearch, Logstash, Kibana e Beats, sendo que o último foi adquirido recentemente. Todos os projetos são desenvolvidos, gerenciados e mantidos pela Elastic.
Juntos, esses componentes são mundialmente usados para monitorar, solucionar problemas e proteger ambientes de TI (embora haja muitos outros casos de uso para o ELK Stack, como business intelligence e web analytics). O Beats e o Logstash cuidam da coleta e do processamento de dados, o Elasticsearch indexa e armazena os dados e o Kibana fornece uma interface de usuário para consultar os dados e visualizá-los.
Logo abaixo veremos um pouco mais sobre cada tecnologia.
Logstash
Na sigla ELK (Elasticsearch, Logstash e Kibana), temos como principal tarefa a análise de dados que é dada pela letra “L”.
O Logstash teve o seu início como uma ferramenta de código aberto desenvolvida para lidar com o fluxo de uma grande quantidade de dados de log de várias fontes. Depois de entrar na ELK, ele ficou encarregado também de processar as mensagens de log, melhorando-as e, em seguida, enviando para um destino definido para armazenamento.
Graças a um grande ecossistema de plug-ins, o Logstash pode ser usado para coletar, enriquecer e transformar uma ampla gama de diferentes tipos de dados. Existem mais de 200 plug-ins diferentes para o Logstash, com uma vasta comunidade fazendo uso de seus recursos extensíveis.
Atualmente está na versão 7.0 e vem se tornando uma das peças fundamentais para se trabalhar com logs no grupo ELK.
Kibana
Completamente de código aberto, Kibana é uma interface gráfica feita em navegador que pode ser usada para pesquisar, analisar e visualizar os dados armazenados nos índices Elasticsearch (Kibana não consegue ser usado com outros bancos de dados). Kibana é especialmente conhecido e popular devido aos seus ricos recursos gráficos e de visualização que permitem aos usuários e usuárias explorarem grandes volumes de dados.
O Kibana está disponível para Linux, Windows e Mac, podendo ser instalado por meio do .zip ou tar.gz, repositório do git ou no Docker. Kibana é executado em Node.js e os pacotes de instalação vêm integrados com os binários necessários.
Beats
Beats são uma coleção de remetentes de log de código aberto que agem como agentes instalados em diferentes servidores em seu ambiente para coletar logs ou métricas. Escritos em Go, esses remetentes foram projetados para serem leves por natureza. Eles acabam deixando um pequeno rastro na instalação, mas são eficientes em termos de recursos e funcionam sem dependências.
Os dados que são coletados pelos diferentes Beats variam, arquivos de log no caso do Filebeat, dados de rede no caso do Packetbeat, sistema e métricas de serviço no caso do Metricbeat, logs de eventos do Windows no caso do Winlogbeat e assim por diante. Além dos beats desenvolvidos pelo Elastic, há também uma lista crescente de beats desenvolvidas e contribuídas pela comunidade.
Depois de coletados, você consegue configurar o seu beat para enviar os dados diretamente para o Elasticsearch ou para o Logstash para algum processamento adicional. Alguns beats também conseguem fazer algum processamento, o que ajuda a descarregar parte do trabalho pesado pelo qual o Logstash é responsável.
Desde a versão 7.0, o Beats está dentro das normas do Elastic Common Schema (ECS) introduzido no início de 2019. O ECS visa tornar mais fácil para as pessoas usuárias correlacionar todos os tipos de dados, aderindo a um formato de campo uniforme.
Quais os conceitos básicos do Elasticsearch?
Para entender melhor como funciona o Elasticsearch, devemos entender os seus conceitos básicos de lógica e backend.
Quais os conceitos lógicos do Elasticsearch?
Documentos
O Elasticsearch utiliza o formato JSON como base de seu armazenamento. Com essa ideia, temos os documentos que seriam o ponto inicial de informações indexadas no objeto. Quando pensamos em documentos, podemos comparar com as linhas de um banco de dados tradicional.
Para cada documento temos um identificador único, que chamamos de ID. Ao lado deste campo, conseguimos definir um documento com qualquer tipagem, seja um texto, número, boolean ou até um grande objeto JSON. Isto torna o Elasticsearch muito versátil e útil para qualquer tipo de aplicação.
Índices
Para organizarmos melhor o nosso esquema de documentos, utilizamos a lógica de índices que o Elasticsearch nos oferece. Nela, agrupamos documentos com formas de dados semelhantes, desta forma conseguimos melhorar a performance como um todo e ainda deixar a estrutura bem limpa.
Como exemplo, em um site de livros, conseguimos criar alguns índices padrão, como Livros, que seria o agrupador de documentos que possuem alguma relação com os livros e até Autores, que também seria um agrupador, só que para autores. Cada índice deve ter um nome único e é usado constantemente para executar documentos.
Índices invertidos
No Elasticsearch, índices invertidos são utilizados para alimentar o mecanismo de busca. Isto é, armazenando os conteúdos, de palavras, números e localizações que podem estar presentes em uma entidade menor de documentos. Com isso, criamos um paralelo entre um texto e um documento, de uma maneira bem simples.
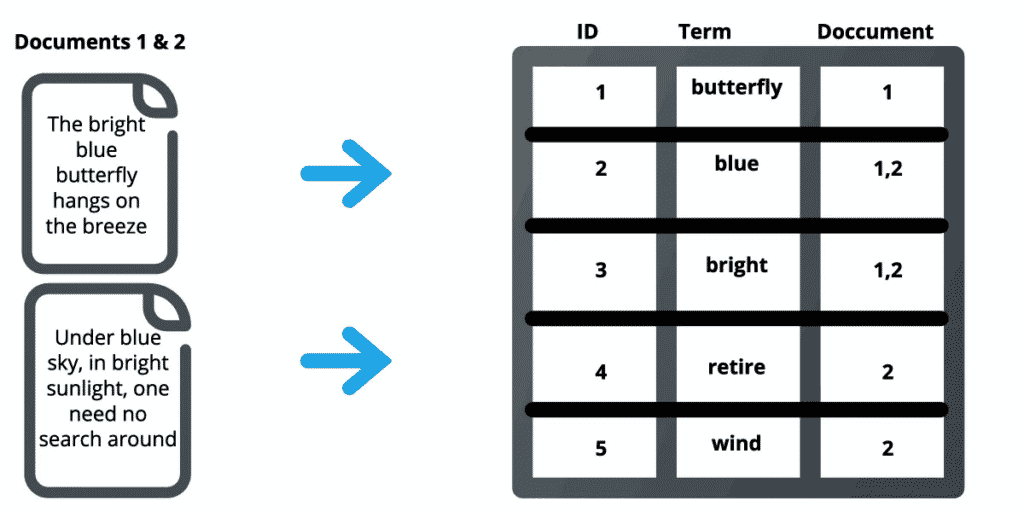
Desta forma, o índice invertido guarda apenas o termo e os possíveis documentos que ele aparece. Sendo assim, quando um novo texto é lido, o Elasticsearch já tem uma resposta para os termos.
Na imagem abaixo, a palavra “butterfly” aparece no primeiro texto. Desta maneira, o mecanismo mapeia tanto um identificador único, o termo em si e em qual documento aparece. O Elasticsearch consegue por meio desta lógica encontrar muito facilmente qualquer tipo de conteúdo, basta que ele esteja treinado para tal.
Quais os conceitos de Backend do Elasticsearch?
Agora vamos dar uma olhada nas lógicas que o Elasticsearch usa para organizar toda a sua ferramenta.
Conjunto
Um conjunto, nada mais é do que um Cluster que agrupa vários Nós (Nodes), e tem o objetivo de distribuir logicamente as tarefas, indexação e pesquisas destes Nós.
Node
Node, ou nó em português, é uma espécie de servidor que guarda os dados e realiza a indexação destas informações, dentro de um cluster. Dentro do Elasticsearch, um nó tem alguma atribuições a ele, tais como:
- Nó mestre: É o principal nó que controla as ações de um cluster. Tem como principais funções realizar a criação e exclusão de índices e adicionar ou remover mais nós, casos seja necessário.
- Nó de dados: Realiza todo o esquema de pesquisas e agrupamento de dados, desta forma também armazenando e executando tarefas relacionadas ao dados no geral.
- Nó cliente: É o campo de entrada para qualquer tipo de solicitação para o nó mestre ou então o nó de dados, sendo assim não exerce nenhum papel fundamental.
Shards
Para cada índice, conseguimos subtrair informações e recriar vários shards, que seriam fragmentos em português. Podemos dizer que um shard é uma parte de índice totalmente funcional e que é independente para ser adicionado ou não em algum node.
Esta é uma estratégia de redundância, e o Elasticsearch realiza isto para se proteger de possíveis falhas no hardware e até mesmo aumentar o nível de consultas em paralelo. Com os fragmentos criados, o trabalho fica por parte dos nós que devem gerenciá-los.
Réplicas
Para aumentar ainda mais a redundância, o mecanismo do Elasticsearch nos oferece um sistema de réplica dos fragmentos, fazendo com que shards sejam chamadas de “replica shards”
Estas réplicas tem como objetivo ajudar também a combater possíveis falhas que acometem os aparelhos, e também a melhorar a performance como um todo. Aumenta a capacidade na busca de dados, pesquisa e até recuperação de documentos.
Elasticsearch Query DSL: o que é e como usar?
Elasticsearch nos fornece a ajuda da query DSL para solicitar pesquisas de corpo de solicitação mais avançadas. Isso é, nesse tipo de pesquisa, temos uma grande variedade de opções disponíveis e podemos misturar e combinar diferentes opções para obter os resultados que desejamos.
Existem dois tipos de query: 1) leaf query que procura um valor em um campo específico e 2) compound query, que pode conter uma ou várias leaf query)
Tipos de consulta Elasticsearch
Há uma grande variedade de opções disponíveis nesses tipos de pesquisa, e você pode misturar e combinar diferentes opções para obter os resultados que deseja. Os tipos de consulta que existem são:
- Consulta geográfica
- Consulta “mais semelhante a isto”
- Consulta com script
- Consulta de texto completo
- Consulta de formas
- Consulta de abrangência
- Consulta em nível de termo
- Consulta especializada
A partir da versão 6.8 do Elasticsearch, o ELK Stack juntou as consultas das queries e filtros do Elasticsearch. No entanto, o Elasticsearch ainda os diferencia por contexto. A DSL distingue entre um contexto de filtro e um contexto de consulta para cláusulas de consulta. Utilizando as cláusulas em um contexto de filtro, é testado os documentos de forma booleana: o documento corresponde ao filtro, “sim” ou “não“?
Os filtros também são geralmente mais rápidos do que as consultas em si, porém as consultas também conseguem calcular uma pontuação de relevância de acordo com o grau de correspondência de um documento com a consulta. Os filtros não utilizam uma pontuação de relevância.
Como funciona o Elasticsearch?
O ElasticSearch mantém um conjunto de mecanismos integrados para sempre produzir os resultados da melhor forma possível. Esse trabalho se dá da seguinte forma:
- todos os documentos são indexados, ou seja, registrados em um banco de dados;
- cada arquivo é analisado por um algoritmo responsável por separar os seus termos em tokens únicos;
- uma medição desses tokens é realizada para identificar quais possuem maior relevância e que artigos, preposições e itens de pouca relevância podem ser descartados sem comprometer o resultado final;
- os tokens filtrados são organizados em um novo índice, que define em quais documentos cada token aparece.
Sempre que uma busca for realizada, o Elasticsearch fará uma análise sobre o índice invertido. Isso permite a ele obter os resultados rapidamente, sem ter que vasculhar todos os documentos individualmente em busca de dados.
Essa característica transforma-o em uma ferramenta de buscas quase em tempo real. Tudo isso por um custo baixo.
Outra funcionalidade que torna o Elasticsearch único é a filter. Ela utiliza um cache — mecanismo para salvar dados por um curto período — para realizar buscar repetidas. Isso reduz o uso das capacidades computacionais e garante que a entrega de dados seja muito mais rápida: em vez de repetir todo o processo de busca, o recurso encontrará o resultado pronto em uma área temporária e de fácil acesso.
Se a busca for feita por querys, a ferramenta também consegue se destacar frente a outras soluções. É possível ranquear dados por relevância. Assim, as pessoas que fazem uso da tecnologia podem encontrar o que precisam em um tempo muito menor.
Por que usar o Elasticsearch?
Existem vários motivos para utilizar o Elastisearch no seu dia a dia. Eles estão relacionados ao impacto que a solução terá na sua rotina a partir das suas funcionalidades. Podemos apontar como os principais benefícios:
- a possibilidade de ter acesso a dados quase em tempo real;
- a alta capacidade de lidar com dados em grande volume sem apresentar gargalos;
- a elasticidade da aplicação;
- o fato de ser um software de código aberto;
- os recursos de geolocalização e analytics integrados nativamente;
- as APIs e DSLs de consulta que podem ser integradas à ferramenta.
A alta performance e escalabilidade tornam o Elasticsearch mais adaptável a diferentes ambientes. Mesmo em equipes que mantêm um ciclo de trabalho de alta performance, a sua adoção será feita com alta confiabilidade. Afinal, todos terão a garantia de que o recurso poderá lidar com a demanda facilmente.
Por ser um sistema de código aberto, a auditoria do código-fonte pode ser feita sem medo. Além disso, o Elasticsearch pode ser personalizado conforme as suas demandas. Com as APIs e as DSLs, ampliam-se os cenários em que ele pode ser adotado no seu dia a dia.
Quais as desvantagens do Elasticsearch?
Como qualquer outra ferramenta, o Elasticsearch também tem suas desvantagens, as principais são:
- Não oferece suporte a vários idiomas para lidar com dados de solicitação e respostas.
- Elasticsearch não é um bom armazenamento de dados, bem como outras opções como MongoDB, Hadoop, etc. Ele tem um bom desempenho para pequenos casos de uso, mas no caso de streaming de dados de TB por dia, ele acaba sendo o gargalo da operação.
- A curva de aprendizado não é muito boa, mesmo sendo bem poderoso e flexível, não é tão simples querer aprender a mexer com essa ferramenta.
Por ser uma ferramenta com um potencial enorme, o Elasticsearch acaba pecando em coisas relativamente simples. Os conceitos e lógicas que devemos entender antes de começar a realmente utilizar a ferramenta é algo que pode ser uma barreira para muitos projetos. Podemos acabar optando por outras opções com custo parecido e que nos oferecem uma experiência um pouco mais tranquila.
Onde usar o Elasticsearch?
Existem vários ambientes em que o Elasticsearch pode ser utilizado. Em todos os casos, uma instalação segura deve ser feita seguindo a documentação oficial. Assim, você pode garantir que os controles e ajustes estarão dentro dos padrões adequados e a performance sempre será a melhor possível.
Os cenários em que essa solução é utilizada geralmente envolvem:
- sites de e-commerce;
- aplicativos de comparação de preços;
- aplicações que trabalham com a análise de um grande volume de textos e documentos;
- sistemas que precisam de funcionalidades apoiadas no Full Texto Search;
- empresas de BI;
- soluções para identificar as tendências do mercado.
Esses são cenários em que se faz imprescindível o acesso a dados relevantes o mais rápido possível, logo o Elasticsearch pode ser um grande aliado.
Quais as diferenças entre Splunk e Elasticsearch?
Splunk e o Elasticsearch usam duas abordagens diferentes para resolver o mesmo problema. As pessoas normalmente escolhem um ou outro com base em como os seus dados estão estruturados e quanto tempo desejam dedicar à análise de log. O Splunk pega uma pilha de dados e permite que as pessoas pesquisem as informações para extrair o que precisam. Já o Elasticsearch requer mais trabalho e planejamento no início, mas a extração de valor é mais fácil no final.
Os três principais componentes do Splunk são:
- Encaminhador, que envia os dados para os indexadores remotos.
- indexador, que tem a função de armazenar e indexar os dados e responder a solicitações de pesquisa.
- Search Head, que é a interface do front-end web onde os componentes podem ser combinados ou distribuídos em servidores.
O Splunk também oferece suporte a integração de suas funcionalidades em aplicativos via SDKs. Alguns casos de uso comuns incluem o monitoramento operacional, segurança e análise do comportamento do usuário. Splunk é um serviço pago em que o faturamento é gerado de acordo com a indexação do volume.
Juntamente com o Elasticsearch, temos os outros produtos da ELK Stack, Logstash, Kibana e Beats, como já comentamos anteriormente. Todos existem para auxiliar o trabalho com o Elasticsearch.
Tanto o Splunk quanto o Elasticsearch podem ser usados para monitorar e analisar a infraestrutura em operações de TI, bem como para monitoramento de aplicativos, segurança e inteligência de negócios.
Como usar o Elasticsearch? Tutorial com passo a passo!
Para utilizarmos o Elasticsearch localmente é bem simples, basta que você faça o download do Elasticsearch para a versão do seu sistema operacional, aqui temos opções para vários tipos de sistemas.
Logo depois que você baixar o arquivo, você terá que descompactá-lo com algum programa que entenda o formato .zip, o software 7Zip é uma boa recomendação.
Quando você entrar na pasta do Elasticsearch, procure o diretório bin e logo em seguida o arquivo elasticsearch ou elasticsearch.bat se você estiver usando o Windows:

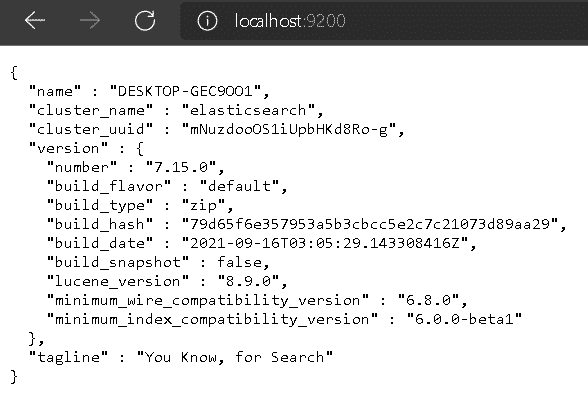
Execute o arquivo e, pronto, temos o nosso próprio ambiente do Elasticsearch rodando localmente. Para testar a sua aplicação rode o comando curl http://localhost:9200/ ou acesse a página diretamente de um navegador.
Como visualizar os dados do Elasticsearch?
Para visualizarmos os dados que estamos utilizando, podemos também rodar a interface gráfica Kibana. Para fazer isso, faça o download da versão que é compatível com seu sistema operacional e já faça a descompactação da pasta.
Para configurar o Elasticsearch no Kibana, entre no arquivo config/kibana.yml e procure o parâmetro elasticsearch.hosts. Se você não mudou a configuração inicial do Elasticsearch, não vai ter nenhum problema.
Agora vamos executar a aplicação, entre na pasta bin e procure um arquivo chamado kibana ou kibana.bat se você estiver usando o Windows. Executado o programa, abre o seu navegador e entre no link http://localhost:5601 para visualizar os dados do Elasticsearch:
Como instalar o Elasticsearch em um container Docker?
Para utilizamos o Elasticsearch em um container no Docker, precisamos apenas rodar esses três comandos no terminal:
docker network create elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.15.0
docker run --name es01-test --net elastic -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.15.0
Quando os três comandos estiverem finalizados, basta seguir o fluxo normal do Elasticsearch.
Se quisermos rodar o Kibana a partir do Docker, também conseguimos, rode o seguinte comando no seu terminal:
docker pull docker.elastic.co/kibana/kibana:7.15.0
docker run --name kib01-test --net elastic -p 5601:5601 -e "ELASTICSEARCH_HOSTS=http://es01-test:9200" docker.elastic.co/kibana/kibana:7.15.0
Após isso, acesse a página do Kibana, http://localhost:5601/.
3 exemplos de consultas e usos do Elasticsearch!
Mostraremos para você o poder do Elasticsearch em ação. Antes de tudo, você deve ter o ambiente tanto do Elasticsearch como o do Kibana rodando e deve acessar a página do console do Elasticsearch, você visualizará algo assim:
Testando uma query simples
Para iniciarmos, criaremos alguns dados para os nossos testes. No console, executaremos os seguintes comandos:
PUT empregados
PUT empregados/_mapping
{
"properties": {
"data_de_nascimento": {
"type": "date",
"format": "dd/MM/yyyy"
}
}
}Dessa forma temos mapeado o tipo Empregado que vamos usar nos nossos testes.
Vamos adicionar alguns dados para o Elasticsearch. Para isso, execute o seguinte comando no terminal:
POST _bulk
{ "index" : { "_index" : "empregados", "_id" : "1" } }
{"id":1,"nome":"Huntlee Dargavel","email":"[email protected]","genero":"male","endereco_ip":"58.11.89.193","data_de_nascimento":"11/09/1990","compania":"Talane","cargo":"Research Associate","experiencia":7,"pais":"China","frase":"Multi-channelled coherent leverage","salario":180025}
{ "index" : { "_index" : "empregados", "_id" : "2" } }
{"id":2,"nome":"Othilia Cathel","email":"[email protected]","genero":"female","endereco_ip":"3.164.153.228","data_de_nascimento":"22/07/1987","compania":"Edgepulse","cargo":"Structural Engineer","experiencia":11,"pais":"China","frase":"Grass-roots heuristic help-desk","salario":193530}
{ "index" : { "_index" : "empregados", "_id" : "3" } }
{"id":3,"nome":"Winston Waren","email":"[email protected]","genero":"male","endereco_ip":"202.37.210.94","data_de_nascimento":"10/11/1985","compania":"Yozio","cargo":"Human Resources Manager","experiencia":12,"pais":"China","frase":"Versatile object-oriented emulation","salario":50616}
{ "index" : { "_index" : "empregados", "_id" : "4" } }
{"id" : 4,"nome" : "Alan Thomas","email" : "[email protected]","genero" : "male","endereco_ip" : "200.47.210.95","data_de_nascimento" : "11/12/1985","compania" : "Yamaha","cargo" : "Resources Manager","experiencia" : 12,"pais" : "China","frase" : "Emulation of roots heuristic coherent systems","salario" : 300000}
Aqui temos uma massa com alguns dados aleatórios. Para fazermos a pesquisa pelo Elasticsearch precisaremos executar uma simples query, da seguinte maneira:
POST empregados/_search
{
"query": {
"match": {
"compania": {
"query" : "Yozio"
}
}
}
}Aqui fazemos uma breve pesquisa de pessoas funcionárias que estão na empresa Yozio. O resultado deverá ser o seguinte:

Apenas uma pessoas foi encontrada.
Query booleana
Os operadores AND, OR e NOT podem ser usados para ajustar nossas consultas a fim de fornecer resultados mais relevantes. Nesse tipo de consulta, devemos passar o parâmetro must (equivalente a AND), um parâmetro must_not (equivalente a NOT) e um parâmetro deve (equivalente a OR). Por exemplo, se você quiser pesquisar uma pessoa que trabalhe na “Edgepulse” ou “Yamaha”, que seja da “China” e que não tenha um salário de “180025”:
POST empregados/_search
{
"query": {
"bool": {
"must": {
"bool" : {
"should": [
{ "match": { "frase": "Edgepulse" }},
{ "match": { "frase": "Yamaha" }}
],
"must": { "match": { "pais": "China" }}
}
},
"must_not": { "match": {"salario": 180025 }}
}
}
}E o resultado será esse:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.10536051,
"hits" : [
{
"_index" : "empregados",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.10536051,
"_source" : {
"id" : 2,
"nome" : "Othilia Cathel",
"email" : "[email protected]",
"genero" : "female",
"endereco_ip" : "3.164.153.228",
"data_de_nascimento" : "22/07/1987",
"compania" : "Edgepulse",
"cargo" : "Structural Engineer",
"experiencia" : 11,
"pais" : "China",
"frase" : "Grass-roots heuristic help-desk",
"salario" : 193530
}
},
{
"_index" : "empregados",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.10536051,
"_source" : {
"id" : 3,
"nome" : "Winston Waren",
"email" : "[email protected]",
"genero" : "male",
"endereco_ip" : "202.37.210.94",
"data_de_nascimento" : "10/11/1985",
"compania" : "Yozio",
"cargo" : "Human Resources Manager",
"experiencia" : 12,
"pais" : "China",
"frase" : "Versatile object-oriented emulation",
"salario" : 50616
}
},
{
"_index" : "empregados",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.10536051,
"_source" : {
"id" : 4,
"nome" : "Alan Thomas",
"email" : "[email protected]",
"genero" : "male",
"endereco_ip" : "200.47.210.95",
"data_de_nascimento" : "11/12/1985",
"compania" : "Yamaha",
"cargo" : "Resources Manager",
"experiencia" : 12,
"pais" : "China",
"frase" : "Emulation of roots heuristic coherent systems",
"salario" : 300000
}
}
]
}
}Query Fuzzy
A Query Fuzzy pode ser usada em pesquisas múltiplas para detectar erros de ortografia, por exemplo. O grau da imprecisão é especificado com base na distância de Levenshtein da palavra original, ou seja, o número de alterações de um caractere que precisam ser feitas em um string para torná-la igual a outra string.
POST empregados/_search
{
"query": {
"multi_match" : {
"query" : "Othilio Versatila",
"fields": ["nome", "frase"],
"fuzziness": "AUTO"
}
},
"size": 2
}Aqui procuramos duas palavras que estão erradas em dois campos, nome e frase. O Elasticsearch encontra dois empregados que deram match:
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.1440992,
"hits" : [
{
"_index" : "empregados",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.1440992,
"_source" : {
"id" : 3,
"nome" : "Winston Waren",
"email" : "[email protected]",
"genero" : "male",
"endereco_ip" : "202.37.210.94",
"data_de_nascimento" : "10/11/1985",
"compania" : "Yozio",
"cargo" : "Human Resources Manager",
"experiencia" : 12,
"pais" : "China",
"frase" : "Versatile object-oriented emulation",
"salario" : 50616
}
},
{
"_index" : "empregados",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0319767,
"_source" : {
"id" : 2,
"nome" : "Othilia Cathel",
"email" : "[email protected]",
"genero" : "female",
"endereco_ip" : "3.164.153.228",
"data_de_nascimento" : "22/07/1987",
"compania" : "Edgepulse",
"cargo" : "Structural Engineer",
"experiencia" : 11,
"pais" : "China",
"frase" : "Grass-roots heuristic help-desk",
"salario" : 193530
}
}
]
}
}Quais os principais comandos usados no Elasticsearch?
Se você estiver utilizando o curl em conjunto com o Elasticsearch, saiba que existem alguns comando que podem ajudar na hora de testar a sua ferramenta, dê uma olhada:
Testar uma query
O seguinte comando retorna todos os dados de um index.
curl -XGET environment_url:9200/nome_do_index/_search?Se colocarmos pra ele buscar pelo index Empregados, vai retornar todos os dados já cadastrados.
Verificar os aliases dos indexes
Isso ajuda a verificar se as rotas de solicitação ES correspondem aos índices de índice. O seguinte comando retornará todos os aliases para cada índice:
curl -XGET environment_url:9200/_aliases\?pretty\=true3 empresas que já usaram o Elasticsearch!
Walmart
No Walmart, como qualquer outra empresa grande de vendas, utiliza o Elasticsearch para melhorar o processamento das pesquisas de pessoas usuárias no site deles e com isso adquirir novos conhecimentos e tendências. A análise pelo desempenho da loja e a análise nos dias de feriado são os principais pontos destacados pela empresa.
Também é utilizado o sistema de segurança por SSO do ELK, alertas para erros e um gerenciador de DevOps.
Netflix
Na Netflix, o uso do Elasticsearch é muito focado no monitoramento e análise do atendimento ao cliente, pela busca de termos e textos. Os logs de segurança também são uma prática utilizada.
A escolha pela ferramenta se deve ao fato de ter uma plataforma flexível e fragmentada com um bom ecossistema de plugins que dá oportunidades para a empresa escolher o melhor caminho para o sistema.
Por ser uma empresa gigantesca, o Netflix é um dos casos de mais sucesso do Elasticsearch, principalmente pelas suas enormes implementações com vários clusters e centenas de nós.
Ebay
O principal serviço que o Ebay utiliza é o famoso “Elasticsearch-as-a-Service“, em que a partir da sua estrutura em nuvem baseada em OpenStack, a análise de textos para o negócio vem se mostrado muito importante para o site como um todo.
Um bom instrumento para utilizar com o Elasticsearch é a Kibana. Ela facilita a visualização de dados e se integra facilmente ao recurso. Mas não se esqueça de manter as ferramentas em servidores diferentes.
Todo mundo que utiliza tecnologia, em algum momento, fará uma busca por dados. Nessas horas é importante ter mecanismos para encontrar e filtrar os registros rapidamente. Afinal de contas, em muitos casos o tempo é algo crucial para garantir que a informação seja relevante.
O Elasticsearch é uma das melhores soluções para trabalhar com a busca e a filtragem de dados, sendo também altamente confiável e personalizável por se tratar de um código aberto. Por isso, não deixe de considerá-lo em seus projetos de TI!
Quer saber mais sobre como o processamento de dados funciona? Então, confira o nosso post sobre o tema!


