
Você já ouviu falar no termo Data Science ou Ciência de Dados? Se a sua resposta for não, saiba que na área de ti é uma profissão bastante requisitada em empresas de diversos segmentos. Com a transformação digital, muitos negócios passaram a apostar em recursos tecnológicos para, entre outras coisas, reduzir custos e aprimorar processos internos.
Além disso, vale salientar que as empresas carecem de profissionais com capacitação. Em outras palavras, muitas estratégias corporativas nos dias de hoje são baseadas em dados que foram processados, cruzados e correlacionados.
Neste conteúdo que preparamos, você verá:
- O que é Data Science?
- Qual a importância de Data Science e onde ela é usada?
- Quais são as 6 principais fases do processo do Data Science?
- Exemplo de uso do Data Science na prática!
- Quais as diferenças entre Data Science e Data Analytics?
- Quais as diferenças entre Data Science e Big Data?
- Quais as diferenças entre Data Science e Data Warehouse?
- Quais as diferenças entre Data Science e BI?
- Qual a relação entre Data Science e IA?
- O que é a Estatística aplicada ao Data Science?
- Quais as vantagens de trabalhar com Data Science?
- Quais as desvantagens de trabalhar com Data Science?
- Como se tornar um Data Scientist?
- Quais as 5 ferramentas mais usadas em Data Science?
Boa leitura!
O que é Data Science?
Consiste em uma área que abrange diferentes conhecimentos, como matemática, programação, estatística e negócios. Seu objetivo é pegar um grande volume de dados, processar e transformar em informações úteis.
Muitas das vezes, os dados estão desestruturados e sem nenhuma correlação clara. Durante as etapas de coleta, análise e tratamento, eles passam a ser cruzados e correlacionados. Desse modo, torna-se possível entregar informações que auxiliem as pessoas da gestão a obter insights e tomar decisões empresariais com precisão e menor margem de erro.

Qual a importância de Data Science e onde ela é usada?
Com a transformação digital, as empresas precisam adotar tecnologias que as tornem mais competitivas. Além disso, o foco em quem paga e usufrui do serviço passa a ser uma preocupação constante. A pessoa Data Science é fundamental nesse aspecto, uma vez que cruza e correlaciona dados de diversas fontes do negócio.
Com isso, a companhia terá os meios para traçar novas estratégias, além de realizar ajustes em rotinas e processos internos. Conheça abaixo algumas formas de aplicação do Data Science!
Mercado de seguros
Na hora de precificar o serviço, as companhias de seguro devem analisar uma série de variáveis. Com o auxílio do Data Science, as empresas do setor conseguem fazer esse cálculo com maior nível de precisão. Dessa forma, os serviços que são pagos de fato refletem os riscos que foram levantados. Assim, a companhia pode se antecipar melhor aos imprevistos que podem acontecer.
Padrões e comportamentos de consumo
Muitas empresas usam os chamados sistemas de recomendação, recursos em que a pessoa consumidora avalia o serviço oferecido. Com base nos padrões e comportamentos, as empresas passam a oferecer opções de forma personalizada. Um exemplo é o sistema de recomendação da Netflix. Com base nos filmes e séries preferidos das pessoas, os algoritmos processam todas as informações e apresentam ao final as melhores opções para clientes.
Medicina
O trabalho repetitivo de preencher prontuários pode ser feito por software, fazendo a pessoa ter uma maior dedicação para com pacientes. Além disso, a Data Science ajuda na obtenção de diagnósticos precisos, de modo a aperfeiçoar e complementar o trabalho do médico. A ciência dos dados também contribui na análise preditiva, que consiste em identificar com antecedência as doenças que uma pessoa pode ter no futuro.
Quais são as 6 principais fases do processo do Data Science?
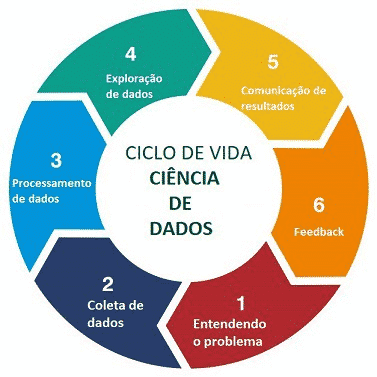
1. Descoberta
Como o primeiro passo no processo de ciência de dados, a descoberta também é sem dúvida a mais importante. Se você acertar as bases, o resultado final do seu projeto provavelmente será de maior valor.
Definir especificações, requisitos, prioridades e um orçamento ajudará a entender se você tem os recursos certos para assumir um projeto, se coletou dados confiáveis suficientes e se o valor potencial do projeto supera seu custo.
Uma vez que isso esteja certo, sua equipe de dados pode delinear o problema que sua empresa precisa resolver e formular hipóteses iniciais para testar. Em outras palavras, esses pontos podem definir como será um projeto de sucesso.
2. Preparação dos dados
Antes de começar a testar suas hipóteses, seus dados (retirados de seus próprios bancos de dados ou por meio de ferramentas de extração de dados) devem ser pré-processados e condicionados. Isso envolve configurar um ambiente de sandbox (teste) e extrair, transformar e carregar seus dados em um formato pronto para análise e construção de modelo.
Então, seus dados podem ser condicionados, pesquisados e visualizados. A visualização de dados pode envolver representação gráfica e/ou dashboards e relatórios personalizáveis, dependendo da ferramenta escolhida.
Mas, com todas as ferramentas de visualização, esta etapa ajuda a identificar e potencialmente remover anomalias, deixando-o com dados relevantes e limpos.
É nesta fase que se estabelece a relação entre todos os seus diferentes conjuntos de dados, o que ditará quais características de dados serão úteis para o seu modelo de ciência de dados na busca de uma solução para o seu problema.
As ferramentas de limpeza e refinamento de dados podem ser incorporadas ao seu banco de dados central, o que garantiria que problemas como duplicação de registros fossem corrigidos automaticamente antes que pudessem afetar adversamente sua própria preparação de dados.
3. Planejamento do modelo
Depois de mapear suas metas de negócios e coletar uma grande quantidade de dados (estruturados, não estruturados ou semiestruturados), é hora de construir um modelo que utilize os dados para atingir a meta.
Existem várias técnicas disponíveis para carregar dados no sistema e começar a estudá-los:
- O ETL (Extrair, Transformar e Carregar) transforma os dados primeiro usando um conjunto de regras de negócios, antes de carregá-los em um sandbox.
- O ELT (Extrair, Carregar e Transformar) primeiro carrega dados brutos no sandbox e depois os transforma.
- ETLT (Extrair, Transformar, Carregar, Transformar) é uma mistura e tem dois níveis de transformação.
Esta etapa também inclui o trabalho em equipe para determinar os métodos, técnicas e fluxo de trabalho para construir o modelo na fase subsequente. A construção do modelo começa com a identificação da relação entre os pontos de dados para selecionar as variáveis-chave para, posteriormente, encontrar o modelo adequado.
4. Construção do modelo
Esta etapa da arquitetura de análise de dados compreende o desenvolvimento de conjuntos de dados para fins de teste, treinamento e produção. As pessoas especialistas em análise de dados constroem e operam meticulosamente o modelo que projetaram na etapa anterior.
Essas pessoas contam com ferramentas e várias técnicas como árvores de decisão, técnicas de regressão (regressão logística) e redes neurais para construir e executar o modelo. Elas também realizam um teste do modelo para observar se o modelo corresponde aos conjuntos de dados.
5. Operacionalização
Nesse estágio, você começa a executar o modelo escolhido e entrega os relatórios finais sobre as descobertas de desempenho do modelo, bem como os briefings, códigos e documentos técnicos necessários.
Se o seu modelo funcionou melhor do que o esperado, é nesta fase que você pode montar um projeto piloto de pequena escala fora do ambiente sandbox, em um ambiente de produção em tempo real, para começar a verificar a eficácia da aplicação no mundo real.
Isso revelará quaisquer restrições imprevistas que precisarão ser consideradas antes que seu modelo possa ser totalmente colocado em uso. Uma API adequada será necessária para começar a processar as saídas do modelo online, fora do ambiente de sandbox.
6. Comunicação dos resultados
Os resultados do seu projeto podem agora ser comunicados e comparados com as hipóteses iniciais definidas na primeira fase do ciclo de vida, para determinar se os dados revelaram os insights esperados e se o seu modelo funcionou de forma a resolver o problema inicial.
Se seu processo precisa ser refinado para melhorar a qualidade de seus resultados, você pode começar novamente na fase um com um problema mais específico para resolver. A cada refinamento, seu modelo fica mais próximo de estar pronto para implantação em um ambiente em tempo real.
Após a entrega e a implantação, o ciclo de vida continua. A eficácia do seu modelo deve ser continuamente monitorada e testada para garantir que ele forneça valor ao seu negócio e à pessoa consumidora. Os dados mudam rapidamente ao longo do tempo e seu modelo precisará se ajustar às novas tendências para evitar a regressão de desempenho.
Exemplo de uso do Data Science na prática!
Sistema de recomendação de hotéis
Um sistema de recomendação de hotel normalmente funciona em filtragem colaborativa que faz recomendações com base nas classificações dadas por outras pessoas clientes na mesma categoria de quem procura um produto.
Caso de uso: Todos nós planejamos viagens e a primeira coisa a fazer ao planejar uma viagem é encontrar um hotel. Existem vários sites recomendando o melhor hotel para a nossa viagem.
Um sistema de recomendação de hotéis visa prever qual hotel uma pessoa usuária tem mais probabilidade de escolher entre todos os hotéis. Então, para construir este tipo de sistema que a ajudará a reservar o melhor hotel dentre todos os outros, devemos utilizar os comentários de clientes.
Por exemplo, suponha que você queira fazer uma viagem de negócios. O sistema de recomendação de hotéis deve mostrar os hotéis que outras pessoas classificaram como melhores para viagens de negócios.
Com isso, também é nossa obrigação criar um sistema de recomendação com base nas avaliações e classificações de clientes. Logo, usamos as classificações e avaliações dadas por clientes que pertencem à mesma categoria que quem utiliza e construímos um sistema de recomendação.
Quais as diferenças entre Data Science e Data Analytics?
Abaixo podemos visualizar uma tabela que traz as principais diferenças entre Data Science e Data Analytics.
| Data Science | Data Analytics |
| Data Science é todo o campo multidisciplinar que inclui conhecimento de domínio, aprendizado de máquina, pesquisa estatística, análise de dados, matemática e ciência da computação. | É uma parte significativa da ciência de dados onde os dados são organizados, processados e analisados para resolver problemas de negócios. |
| O escopo da ciência de dados é considerado macro. | O escopo da análise de dados é micro. |
| Um dos campos mais bem pagos em ciência da computação. | É um trabalho bem remunerado, mas inferior ao de um cientista de dados. |
| Requer conhecimento de modelagem de dados, estatística avançada, aprendizado de máquina e conhecimento básico de linguagens de programação como SQL, Python/R, SAS. | Requer sólidos conhecimentos de banco de dados como SQL, habilidades de programação como Python/R, Hadoop/Spark. Também requer conhecimento de ferramentas de BI e conhecimento de estatística de nível médio. |
| A entrada são dados brutos ou não estruturados que são então limpos e organizados para serem enviados para análise. | A entrada é principalmente dados estruturados nos quais os princípios de design e as técnicas de visualização de dados são aplicados. |
| Envolve a exploração de mecanismos de pesquisa, inteligência artificial e aprendizado de máquina. | O escopo é limitado a técnicas analíticas principalmente usando ferramentas e técnicas estatísticas. |
| O objetivo da ciência de dados é encontrar e definir novos problemas de negócios que levem à inovação. | O problema já é conhecido e com analytics, a pessoa analista tenta encontrar as melhores soluções para o problema. |
| Usado para sistemas de recomendação, pesquisa na Internet, reconhecimento de imagem, reconhecimento de fala e marketing digital. | Usado em áreas de domínio como saúde, viagens, turismo, jogos, finanças e assim por diante. |
| Envolve encontrar soluções para problemas novos e desconhecidos, descobrindo-os e convertendo dados em histórias de negócios e casos de uso. | Os dados só passam por análise e interpretação minuciosas, no entanto, não há roteiro criado. |
Quais as diferenças entre Data Science e Big Data?
Abaixo podemos visualizar uma tabela que traz as principais diferenças entre Data Science e Big Data.
| Data Science | Big Data |
| Atividade científica é o principal foco dos dados É uma das abordagens para o processamento do big data Utiliza o big data para as decisões de negócio É parecido com minerar dados | Os bancos de dados tradicionais não podem manipular esse grande número de dados. A base dele é variedade, volume e velocidade |
| É a área especializada que utiliza as ferramentas de programação científica, técnicas e modelos para processar big data Com suas técnicas, ajuda a extrair insights e informações de grandes volumes de dados Apoia a empresa na sua tomada de decisões | Os dados são gerados com base em várias fontes É possível utilizar qualquer tipo e formato de dado |
| Extrai conhecimento aplicando métodos científicos do big data Filtra, prepara e analisa os dados Cria padrões complexos no big data e modelo fluxos | Gravações de áudio/vídeo Fóruns online Dados que são gerados em empresas (transações, banco de dados, etc.) Dados de logs de sistemas |
| Pode ser aplicado em: Pesquisas na internet Recomendadores em sites de busca Detecção de risco e fraude Desenvolvimento na web Também é possível usar em outras áreas | É aplicado em: Estabelecimentos financeiros Telecomunicações Esporte e saúde Organizar o negócio digital Desenvolvimento de pesquisa Segurança de dados e aplicações |
| Precisa de bastante matemática, estatística e ferramentas da área de exatas Algoritmos avançados para minerar os dados Habilidades em linguagens de programação de banco como SQL e NoSQL, e plataformas Hadoop Também pode adquirir, preparar, processar, publicar, preservar ou destruir dados Visualiza dados e os prevê em certas circunstâncias | Aumenta a eficácia do negócio Consegue ganhar competitividade entre várias empresas Vantagem comercial entendendo e usando os tipos de dados Usa ROI realistas e métricas É sustentável por si só Conquista novas pessoas clientes entendendo o mercado |
Quais as diferenças entre Data Science e Data Warehouse?
Um data warehouse é um repositório que armazena dados atuais e históricos de fontes diferentes. É um componente-chave de uma arquitetura de análise de dados que cria um ambiente para suporte a decisões, análises, inteligência de negócios e mineração de dados.
Um data warehouse contém dados de várias fontes, incluindo bancos de dados internos e plataformas SaaS. Depois que os dados são carregados, eles podem ser limpos, transformados, catalogados e verificados quanto à qualidade antes de serem usados para painéis de análise, relatórios, aprendizado de máquina ou qualquer outra coisa.
Historicamente, as empresas usavam ferramentas de ETL para canalizar dados para sistemas caros de data warehouse no local. Devido à capacidade limitada desses sistemas caros, as pessoas usuárias de negócios precisavam realizar o máximo de trabalho de preparação possível antes de carregar os dados no sistema.
Atualmente, no entanto, data warehouses baseados em nuvem, incluindo Amazon Redshift, Microsoft Azure SQL Data Warehouse, Google BigQuery e Snowflake, oferecem infraestrutura flexível cuja capacidade de processamento e armazenamento podem ser dimensionada rapidamente com base nas necessidades de dados de uma organização.
Mais e mais organizações estão optando por ignorar as transformações de pré-carregamento em favor da execução de transformações no momento da consulta — um processo conhecido como ELT. Isso permite que pessoas usuárias de negócios transformem dados brutos em um data warehouse a qualquer momento para qualquer caso de uso específico.
Quais as diferenças entre Data Science e BI?
Abaixo podemos visualizar uma tabela que traz as principais diferenças entre Data Science e Business Intelligence.
| Data Science | Business Intelligence | |
| Complexidade | Alta | Simples |
| Dado | Distribuído e em tempo real | Armazenado |
| Função | É utilizado estatística e matemática em um grupo de dados para entendê-los e conseguir criar modelos e previsões para esse conjunto. | Pode-se dizer que BI é composto por organização, extração e visualização de dados. |
| Uso | É usado principalmente para ajudar as empresas a aumentarem o seu potencial financeiro e também diminuir o risco. | A sua ajuda é focada principalmente em análises de causa em uma falha ou também entender a situação da empresa. |
| Habilidade de Carreira | As principais habilidades necessárias são modelagem de dados, familiaridade com algoritmos e um bom conhecimento nas linguagens R, Python e Scala. | Muitas das tarefas do BI ainda são feitas no Excel. Também é utilizado ferramentas para a visualização de dados como o QlikView, Tableau, etc. |
| Foco | O foco sempre é o futuro do negócio. | É focado principalmente no passado e presente. |
| Tecnologia | O foco hoje em dia é mais na ciência de dados do que em qualquer outra área. Tanto é, que a maioria das empresas sempre buscam profissionais nesse setor. | A visualização de dados do BI pode ser complexa de montar e também de visualizar. |
| Evolução | É praticamente a evolução da inteligência de negócios. | Existe há muito tempo no mercado, mas atualmente conta com uma gama bem maior de ferramentas disponíveis. |
| Processamento | É dinâmica e interativa. A ciência de dados é feita pela experimentação. | Não se tem muita experimentação, e o fluxo é praticamente idêntico: é feita a extração de dados, alterações e por fim a visualização da dashboard. |
| Flexibilidade | A ciência de dados é muito flexível. Os conjuntos de dados conseguem ser adicionados conforme a necessidade. | A flexibilidade no BI é bem complicada, principalmente porque deve-se planejar bastante quando entra mais um novo conjunto de dados. |
| Valor no negócio | Traz um grande valor de negócio, principalmente porque se concentra no futuro dele. | Tem um processo estático mais lento de extrair o valor do negócio, é focado principalmente nos KPIs e gráficos. |
| Processo de pensamento | Ajuda a tirar dúvidas, e incentiva a empresa a funcionar de uma maneira mais eficiente e estratégica. | Ajuda a responder uma pergunta que foi feita. |
| Qualidade dos dados | É o capacitador dos tomadores de decisão, aumenta o nível de confiança. | Oferece uma boa visualização dos dados e pode-se tirar bons insights a partir disso. |
| Função de Especialização | Cientista de dados | Pessoa usuária empresarial |
Qual a relação entre Data Science e IA?
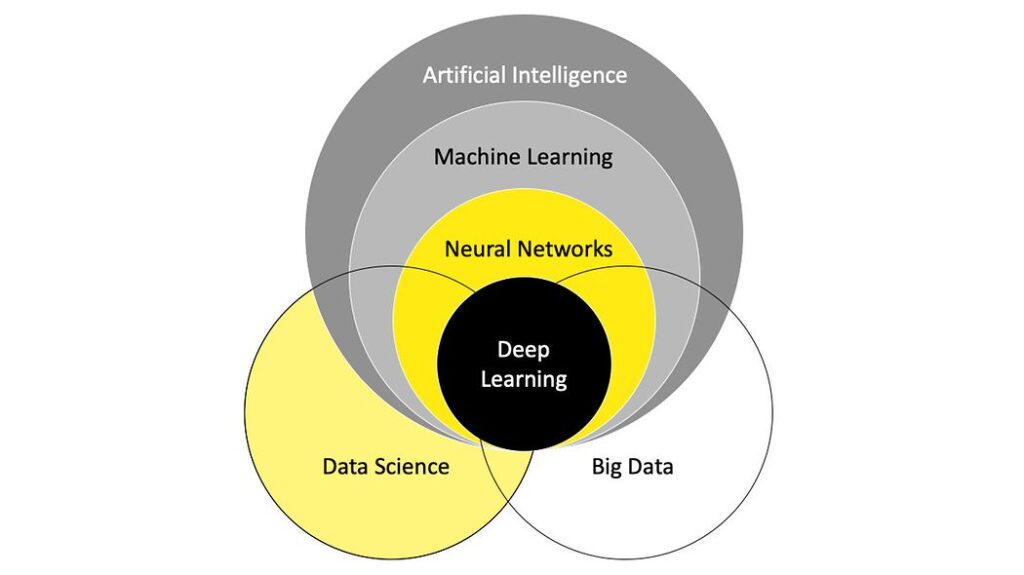
Os campos de inteligência artificial (IA), aprendizado de máquina (ML) e ciência de dados têm muita sobreposição, mas não são intercambiáveis. Existem algumas nuances entre eles. Aqui está uma explicação muito simplificada de como essas três áreas diferem:
- A ciência de dados produz insights
- O aprendizado de máquina produz previsões
- A inteligência artificial produz ações
A ciência de dados é um processo abrangente que envolve várias etapas para analisar dados e gerar insights. Ele gira em torno da ideia de construir modelos que usam insights estatísticos para encontrar padrões ocultos e fazer previsões.
A inteligência artificial faz uso de algoritmos de computador para dar autonomia ao modelo de dados e emular a cognição e a compreensão humana.
O aprendizado de máquina e o aprendizado profundo são subconjuntos e aplicativos avançados de IA que usam vastos conjuntos de dados para treinar os computadores a tirar conclusões.
No caminho para a transformação digital e indústria 4.0, mais e mais empresas incorporam ciência de dados, análise avançada de dados e IA em seus processos de desenvolvimento e produção para melhorar a eficiência, reduzir erros e permanecer competitivos.
Métodos como análise preditiva, monitoramento de análise de dados em tempo real e gêmeos digitais para controle de processos são suportados por métodos e ferramentas de análise de dados.
O que é a Estatística aplicada ao Data Science?
A ciência de dados está enraizada na estatística, pois adota uma abordagem mais puramente matemática para analisar e resolver problemas de dados coletados que geralmente:
- Concentra-se em tirar conclusões precisas sobre “grandes grupos e fenômenos gerais a partir das características observáveis de pequenas amostras que representam apenas uma pequena parte do grande grupo ou um número limitado de instâncias de um fenômeno geral”.
- Aplica ferramentas matemáticas como cálculo e álgebra linear à teoria da probabilidade
- Inclui uma abordagem estatística inferencial ou descritiva
- Oferece processos de solução de problemas exclusivamente úteis ao lidar com conjuntos menores de dados
Existem nuances e exceções nesses campos sobrepostos, mas a ciência de dados é frequentemente usada para fazer previsões e otimizar pesquisas em grandes campos de dados e bancos de dados.
Ele aplica técnicas como ferramentas de aprendizado de máquina e inteligência artificial a problemas que normalmente exigem inteligência humana, mas são muito grandes em escopo para serem resolvidos de maneira mais tradicional com eficiência. A ciência de dados visa fazer previsões precisas de comportamentos e padrões futuros em um determinado mercado ou setor.
A estatística aplicada ainda é crucial para resolver muitos problemas do mundo real e tirar conclusões essenciais para empresas e organizações. Pessoas da área descobrem a melhor forma de coletar dados, fazer medições e quantificar a incerteza nos pontos em que as soluções de ciência de dados baseadas em máquina podem ser difíceis de manejar.
Quais as vantagens de trabalhar com Data Science?
As principais vantagens de se trabalhar com Data Science são:
- Está em demanda
É o trabalho que mais cresce no Linkedin e está previsto para criar 11,5 milhões de empregos até 2026. Isso torna a Ciência de Dados um setor de trabalho altamente empregável.
- Abundância de Cargos
Existem muito poucas pessoas que possuem o conjunto de habilidades necessário para se tornar uma pessoa Cientista de Dados completa. Isso torna o Data Science menos saturado em comparação com outros setores de TI.
Portanto, Data Science é um campo muito abundante e tem muitas oportunidades. O campo da Ciência de Dados é de alta demanda, mas baixa oferta de Cientistas de Dados.
- Uma carreira altamente remunerada
Data Science é um dos trabalhos mais bem pagos. De acordo com a Glassdoor, os cientistas de dados ganham em média R$ 8.000 por mês. Isso torna a Ciência de Dados uma opção de carreira altamente lucrativa.
- A Ciência de Dados é Versátil
Existem inúmeras aplicações da Ciência de Dados. É amplamente utilizado nos setores de saúde, serviços bancários, serviços de consultoria e comércio eletrônico. A Ciência de Dados é um campo muito versátil. Portanto, você terá a oportunidade de trabalhar em vários campos.
- A ciência de dados torna os dados melhores
As empresas exigem pessoas Cientistas de Dados qualificadas para processar e analisar seus dados. Elas não apenas analisam os dados, mas também melhoram sua qualidade.
- As pessoas cientistas de dados são altamente prestigiadas
As pessoas cientistas de dados permitem que as empresas tomem decisões de negócios mais inteligentes. As empresas confiam nelas e usam seus conhecimentos para fornecer melhores resultados a clientes. Isso dá a essas pessoas Cientistas de Dados uma posição importante na empresa.
Quais as desvantagens de trabalhar com Data Science?
Embora a Ciência de Dados seja uma opção de carreira muito lucrativa, também existem várias desvantagens nesse campo. Alguns deles são os seguintes:
- Data Science é um termo confuso
Data Science é um termo muito geral e não tem uma definição definida. Embora tenha se tornado uma palavra da moda, é muito difícil escrever o significado exato do que é ser uma pessoa Cientista de Dados. A função específica de uma Cientista de Dados depende do campo em que a empresa está se especializando.
Enquanto algumas pessoas descreveram a Data Science como o quarto paradigma da Ciência, críticas a chamaram de mera reformulação da Estatística.
- Dominar a ciência de dados é quase impossível
Sendo uma mistura de muitos campos, a Ciência de Dados deriva da Estatística, Ciência da Computação e Matemática. Está longe de ser possível dominar cada campo e ser igualmente especialista em todos eles.
Embora muitos cursos online tenham tentado preencher a lacuna de habilidades que o setor de ciência de dados está enfrentando, ainda não é possível ser proficiente, considerando a imensidão do campo.
Uma pessoa com formação em Estatística pode não ser capaz de dominar Ciência da Computação em curto prazo para se tornar Cientista de Dados proficiente. Portanto, é um campo dinâmico e em constante mudança que exige que a pessoa continue aprendendo os vários caminhos da Ciência de Dados.
- Grande quantidade de conhecimento de domínio necessária
Outra desvantagem do Data Science é sua dependência do Domain Knowledge. Uma pessoa com uma formação considerável em Estatística e Ciência da Computação terá dificuldade em resolver o problema da Ciência de Dados sem o seu conhecimento prévio.
O mesmo vale para o seu vice-versa. Por exemplo, um setor de saúde trabalhando em uma análise de sequências genômicas exigirá um funcionário adequado com algum conhecimento de genética e biologia molecular.
Isso permite que Cientistas de Dados tomem decisões calculadas para auxiliar a empresa. No entanto, torna-se difícil para uma pessoa Cientista de Dados de uma formação diferente adquirir conhecimento de domínio específico. Isso também dificulta a migração de um setor para outro.
- Dados arbitrários podem produzir resultados inesperados
Uma pessoa Cientista de Dados analisa os dados e faz previsões cuidadosas para facilitar o processo de tomada de decisão. Muitas vezes, dados fornecidos são arbitrários e não produzem os resultados esperados. Isso também pode falhar devido à má gestão e má utilização dos recursos.
- Problema de Privacidade de Dados
Para muitas indústrias, os dados são seu combustível. Pessoas Cientistas de Dados ajudam as empresas a tomar decisões baseadas em dados. No entanto, os dados utilizados no processo podem violar a privacidade de clientes.
Os dados pessoais de clientes são visíveis para a empresa-mãe e, por vezes, podem causar vazamentos de dados devido a lapsos de segurança. As questões éticas relacionadas à preservação da privacidade dos dados e seu uso têm sido uma preocupação para muitas indústrias.
Como se tornar um Data Scientist?
Há muitas maneiras de se tornar uma pessoa Cientista de Dados, mas como geralmente é uma posição de alto nível, elas tradicionalmente têm diplomas em matemática, estatística e ciência da computação, entre outros. Isso, no entanto, começou a mudar.
Quais as principais áreas para trabalhar com Data Science?
Existem duas maneiras principais de usar as habilidades de ciência de dados para desenvolver carreiras centradas em dados.
Tornando-se uma pessoa profissional de ciência de dados e buscando empregos como analista de dados, desenvolvedora de banco de dados ou cientista de dados, também é possível exercer uma função habilitada para análise, como analista de negócios funcional ou um gerenciadora de dados.
Ambas as carreiras exigem habilidades e conhecimentos fundamentais em análise de dados, programação, gerenciamento de dados, mineração de dados e visualização de dados.
Apesar das duas faixas, a natureza evolutiva do campo relativamente novo significa que as carreiras são flexíveis.
Profissionais de ciência de dados, como analistas de dados, podem se dedicar a uma função de desenvolvedor de sistemas de dados ou ciência de dados, dependendo de onde aprofundam seus conhecimentos.
Ao expandir o conhecimento em inteligência artificial, estatísticas, gerenciamento de dados e análise de big data, uma pessoa analista de dados pode fazer a transição para uma função de cientista de dados. Com base nas habilidades técnicas existentes em Python, bancos de dados relacionais e aprendizado de máquina, um analista de dados pode se tornar um desenvolvedor de sistemas de dados.
Muitas dessas habilidades podem ser aprendidas com a experiência de trabalho ou de forma independente por meio de cursos online de ciência de dados.
O que faz um Analista de dados?
Analistas de dados são responsáveis por responder a perguntas sobre dados. Ao contrário de cientistas de dados, analistas de dados não estão preocupados em usar dados para encontrar tendências ou descobrir o futuro do negócio.
Seu trabalho é analisar dados históricos, criar e executar testes A/B em produtos e até mesmo projetar sistemas. Analistas de dados precisam ser proficientes no armazenamento e armazenamento de dados e na utilização de ferramentas como o Tableau.
O que faz um Engenheiro de dados?
Engenheiros de dados são pessoas muito técnicas. Elas essencialmente organizam e estruturam os dados brutos para que cientistas de dados e analistas de dados executem seu trabalho.
Uma pessoa engenheiro de dados gosta de construir pipelines de dados e gosta de desenvolver software. Ela tem uma compreensão avançada de linguagens de programação como Java, SQL ou SAS.
O que faz um Desenvolvedor?
Uma pessoa desenvolvedora é o principal indivíduo por trás de todos os aplicativos de software.
Geralmente, as pessoas desenvolvedoras são bem versadas em pelo menos uma linguagem de programação e proficientes na arte de estruturar e desenvolver código de software para software ou programa. Dependendo do cargo e do tipo de software desenvolvido, uma pessoa desenvolvedora pode ser classificada como desenvolvedor de software, desenvolvedor de aplicativos, desenvolvedor móvel, desenvolvedor Web, etc.
Quais as principais habilidades necessárias para ser Data Scientist?
Para se tornar uma pessoa Data Scientist, é preciso dominar algumas habilidades. Agora que você entendeu o conceito, a importância e as aplicações da ciência dos dados, chegou a hora de saber o que fazer no momento de conseguir um trabalho nessa área. Separamos 5 dicas fundamentais para ingressar nesse que é um mercado tão promissor!
1. Conhecimento em programação
Entre as principais linguagens que devem ser dominadas, podemos citar o Javascript, o Python e o R. A primeira é cada vez mais utilizada em aprendizado de máquina. Em relação à segunda, existem diversas técnicas que ajudam a facilitar o tratamento dos dados, sendo que uma delas é a de mapeamento/redução. O Python permite analisar grandes volumes de informações, mesmo se estiverem desestruturadas.
2. Pensamento matemático e lógico
Desenvolver um bom pensamento matemático e lógico ajuda bastante na hora de encontrar as correlações. Além de saber lidar com as linguagens de programação, é preciso ter expertise na hora de lidar com os dados, no intuito de extrair informações relevantes em uma determinada aplicação.
3. Entender sobre negócios
Com a Data Science, é possível prestar o serviço para diversas pessoas clientes, em vez de trabalhar fixo em uma empresa. Atuando desse modo, ficará mais fácil entender o mundo dos negócios, para que se consiga uma boa base de clientes. Nesse sentido, vale ressaltar que muitas pessoas têm um problema e ainda não sabem como resolver.
4. Fazer um curso
Para trabalhar com ciência de dados, fazer um curso voltado para a área é de grande importância. É com ela que se obtém uma grande gama de conhecimentos sobre gestão de banco de dados, Big Data, Business Intelligence, dentre outros. Aliando o estudo com uma prática recorrente, maiores serão as chances de conquistar rapidamente uma vaga em Data Science.
5. Lidar com dados
Uma das razões que justifica o uso de Inteligência Artificial e do Machine Learning é a necessidade de muitas aplicações serem automatizadas. A IA é composta por dados estatísticos, modelos e poder computacional. Os algoritmos envolvidos passam a atuar de forma parecida com o cérebro humano, por meio do aprendizado de máquina, ou Machine Learning.
Deep Learning
O Deep Learning faz uso das chamadas redes neurais, que têm por objetivo tornar uma determinada aplicação a mais humanizada possível. Isso ocorre porque o Deep Learning busca reproduzir o cérebro humano, utilizando o princípio da repetição para fomentar o aprendizado de máquina.
Soft skills
A ciência de dados é uma busca humana. As organizações trazem cientistas de dados para aumentar sua infraestrutura de TI, adicionando um ângulo humanizado e exclusivo e conjuntos de habilidades especializadas. Portanto, além de dominar as habilidades técnicas, pessoas cientistas de dados devem aprimorar suas habilidades sociais para alcançar seu potencial de carreira.
Comunicação
Uma pessoa cientista de dados deve ter um talento especial para vincular a orientação de negócios às facetas científicas, analíticas e técnicas. Eles devem comunicar suas descobertas às pessoas usuárias de negócios e tomadoras de decisão e explicar o valor que esses insights podem trazer para os negócios.
Esta pesquisa deve ser transmitida de forma eficaz para o público técnico e não técnico. Dessa forma, elas podem promover a alfabetização de dados dentro da organização, o que pode destacar sua contribuição e tornar seu papel mais visível em todos os departamentos.
Curiosidade
A curiosidade intelectual inspira cientistas de dados a procurar respostas para lidar com crises de negócios. Profissionais podem ir além das suposições iniciais e resultados superficiais.
Uma pessoa cientista de dados deve ser curiosa o suficiente para descobrir soluções para problemas conhecidos e descobrir insights ocultos e negligenciados. Como resultado, elas obtêm uma maior qualidade de conhecimento de seus conjuntos de dados.
Perspicácia nos Negócios
Cientistas de dados precisam lidar com uma enorme quantidade de conhecimento. Se eles não traduzirem de forma eficaz, essas informações não adiantarão porque o gerenciamento de nível superior nunca consegue usá-las para tomar decisões de negócios.
Logo, elas precisam apreciar as tendências atuais e futuras do setor e adquirir conceitos e ferramentas de negócios básicos.
Narrativa
A narrativa ajuda as pessoas cientistas de dados a transmitir seus resultados de forma lógica e clara.
Isso leva a visualização de dados para outra dimensão, permitindo que quem toma as decisões veja as coisas de uma nova perspectiva. Uma abordagem narrativa convincente cria uma narrativa de dados forte, na qual as partes interessadas obtêm um novo senso de compreensão sobre os dados apresentados e os usam para apoiar suas decisões no futuro.
Adaptabilidade
A adaptabilidade é uma das soft skills mais procuradas em cientistas de dados na aquisição de talentos contemporâneos.
Como a inovação e a implementação tecnológica estão acelerando, profissionais precisam se adaptar rapidamente às tecnologias mais recentes. Como cientista de dados, você precisa ficar atento e responder às mudanças nas tendências de negócios.
Hard skills
Estatística e probabilidade
Quando você começa a aprender a escrever frases, você deve estar familiarizado com a gramática para construir as frases certas, da mesma forma que a estatística é um conceito essencial antes que você possa produzir modelos de alta qualidade. O Machine Learning começa como estatística e depois avança. Mesmo o conceito de regressão linear é um conceito antigo de análise estatística.
Conhecimento em programação
O Machine Learning teve um grande salto apenas por causa do aumento no poder da computação. A programação nos fornece uma maneira de nos comunicarmos com as máquinas. Você precisa se tornar o melhor em programação? De jeito nenhum. Mas você definitivamente precisará se sentir confortável com isso.
Manipulação e Análise de Dados
Você sabe o que separa um grande projeto de aprendizado de máquina do resto? Organização e Análise de Dados. Embora sejam duas etapas diferentes, estão no mesmo ponto por causa da sequência.
A análise de dados geralmente é feita no Excel, SQL, Pandas em Python e é a tarefa mais importante de uma pessoa profissional de análise, enquanto que no aprendizado de máquina a análise de dados é uma etapa de todo o processo.
Visualização de dados
Para começar, você deve estar familiarizado com gráficos como Histograma, gráficos de barras, gráficos de pizza e, em seguida, passar para gráficos avançados, como gráficos em cascata, gráficos de termômetro, etc. Esses gráficos são muito úteis durante o estágio de análise exploratória de dados. As análises univariadas e bivariadas tornam-se muito mais fáceis de entender usando gráficos coloridos.
Aprendizado de máquina
Para uma pessoa cientista de dados, o aprendizado de máquina é a habilidade principal a ter. O aprendizado de máquina é usado para construir modelos preditivos. Por exemplo, se você deseja prever o número de clientes que terá no próximo mês observando os dados do mês anterior, precisará usar algoritmos de aprendizado de máquina.
Como está o mercado de trabalho para Data Scientist?
Cientistas de dados podem trazer insights valiosos que transformam a forma como conduzimos os negócios, levando a soluções melhores e oportunidades de redução de custos. Embora o crescimento da carreira possa mudar de acordo com o setor e a atividade econômica, a ascensão da ciência de dados está em uma tendência geral de alta.
Ao analisar essa tendência, podemos observar onde as oportunidades podem estar mais amplamente disponíveis e como cientistas de dados podem aproveitar ao máximo essas mudanças.
A Glassdoor classifica a ciência de dados como o segundo trabalho mais importante nos Estados Unidos em 2021. Afinal de contas, encontrar padrões e observar correlações são exatamente as habilidades que tornam essas pessoas profissionais de dados tão valiosas nos negócios.
Quanto ganha um Data Scientist?
No Brasil, o cargo de Data Scientist se inicia ganhando em média R$ 3.802,00 de salário e pode vir a ganhar até R$ 10.900,00. A média salarial para Data Scientist no Brasil é de R$ 6.260,00. A formação mais comum é de Graduação em Estatística.
Em alguns casos, pode-se ganhar até mais trabalhando em cargos com mais responsabilidades e experiência na área.
Quais as 5 ferramentas mais usadas em Data Science?
SAS
É uma daquelas ferramentas de ciência de dados projetadas especificamente para operações estatísticas. O SAS é um software proprietário de código fechado usado por grandes organizações para analisar dados. O SAS usa a linguagem de programação básica do SAS para realizar modelagem estatística.
É amplamente utilizado por profissionais e empresas que trabalham em software comercial confiável. O SAS oferece várias bibliotecas e ferramentas estatísticas que você, como Cientista de Dados, pode usar para modelar e organizar seus dados.
Embora o SAS seja altamente confiável e tenha forte suporte da empresa, é muito caro e é usado apenas por indústrias maiores. Além disso, o SAS deixa um pouco a desejar em comparação com algumas das ferramentas mais modernas que são de código aberto.
Python
As ferramentas e tecnologias de Data Science não se limitam a bancos de dados e frameworks. Escolher a linguagem de programação certa para Data Science é de extrema importância. Python é usado por muitas pessoas cientistas de dados para web scraping. O Python oferece várias bibliotecas projetadas explicitamente para operações de Data Science.
Você pode executar com eficiência vários cálculos matemáticos, estatísticos e científicos com o Python. Algumas das bibliotecas Python amplamente utilizadas para Data Science são NumPy, SciPy, Matplotlib, Pandas, Keras, etc.
R
R fornece um ambiente de software escalável para análise estatística e é uma das muitas linguagens de programação populares usadas no setor de Data Science. O agrupamento e a classificação de dados podem ser realizados em menos tempo usando R. Vários modelos estatísticos podem ser criados usando R, suportando modelagem linear e não linear.
Você pode realizar limpeza e visualização de dados com eficiência via R. R representa os dados visualmente de maneira simples para que qualquer pessoa possa entendê-los. O R oferece vários complementos para Data Science, como DBI, RMySQL, dplyr, ggmap, xtable, etc.
Apache Hadoop
Apache Hadoop é um software de código aberto amplamente utilizado para o processamento paralelo de dados. Qualquer arquivo grande é distribuído/dividido em pedaços e depois entregue a vários nós. Os clusters de nós são então usados para processamento paralelo pelo Hadoop. O Hadoop consiste em um sistema de arquivos distribuído responsável por dividir os dados em pedaços e distribuí-los para vários nós.
Além do Hadoop File Distribution System, muitos outros componentes do Hadoop são usados para processar dados paralelamente, como Hadoop YARN, Hadoop MapReduce e Hadoop Common.
Tableau
O Tableau é uma ferramenta de visualização de dados que auxilia na tomada de decisões e na análise de dados. Você pode representar dados visualmente em menos tempo pelo Tableau para que qualquer pessoa possa entendê-los. Problemas avançados de análise de dados podem ser resolvidos em menos tempo por meio dele. Você não precisa se preocupar em configurar os dados enquanto usa o Tableau e pode se concentrar em insights avançados.
Fundado em 2003, o Tableau transformou a maneira como cientistas de dados abordavam os problemas de ciência de dados. Pode-se aproveitar ao máximo seu conjunto de dados usando o Tableau e gerar relatórios perspicazes.
Data Science é um campo relativamente novo com grande potencial de crescimento, além do que já está mostrando atualmente. É uma área que tem alta demanda, muita procura e altos salários.
O desenvolvimento em Data Science é amplo e complexo, sendo uma combinação de elementos da ciência da computação. Nele, temos uma amplitude de tecnologias e palavras chaves que devemos aprender antes de começar um cargo nesta área.
Além de estatística, precisamos aprender linguagens de programação e matemática avançada, para que não haja nenhuma surpresa. Em certas ocasiões, é provável que o profissional dessa área aprenda conhecimentos que vão além da área de tecnologia, como biologia, análise comportamental, entre outras coisas. Esperamos que você tenha aprendido bastante sobre Data Science lendo os textos deste artigo.
Gostou do assunto? Continue no nosso blog e aproveite para ficar por dentro dos passos fundamentais para aprender a programar!


